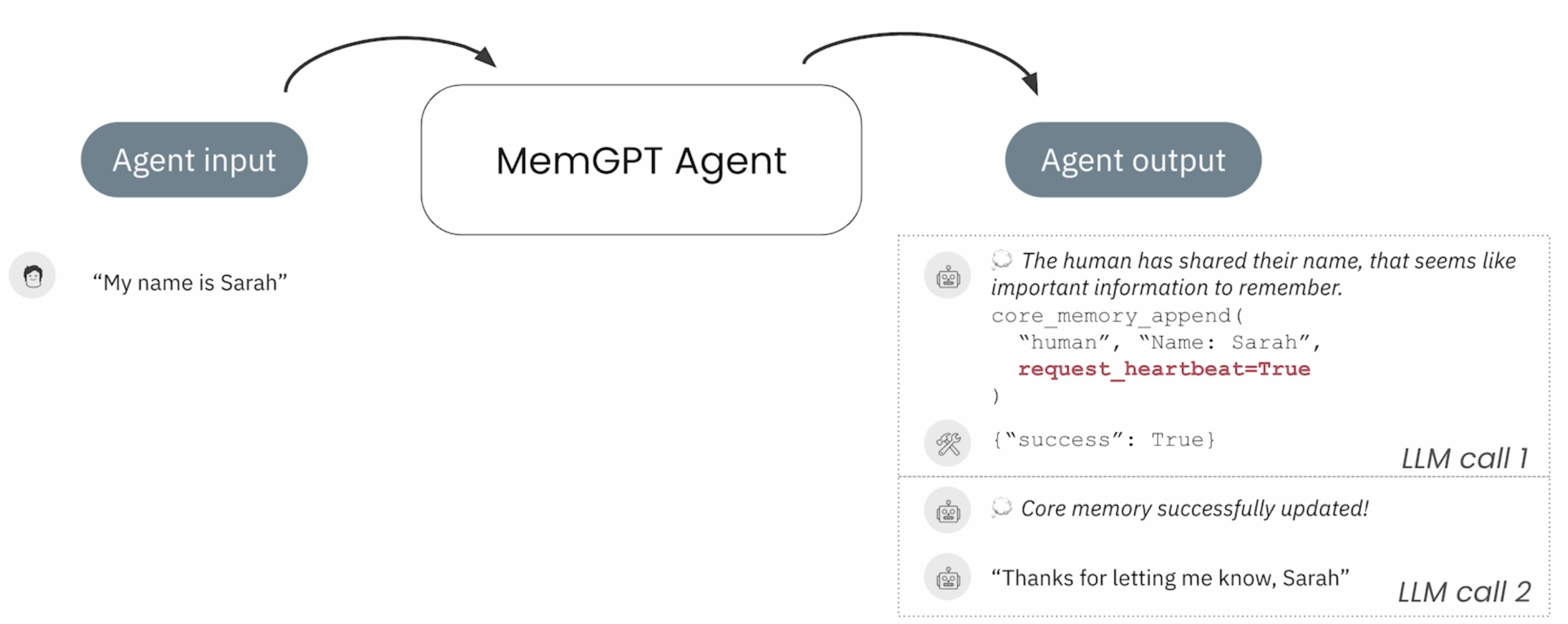
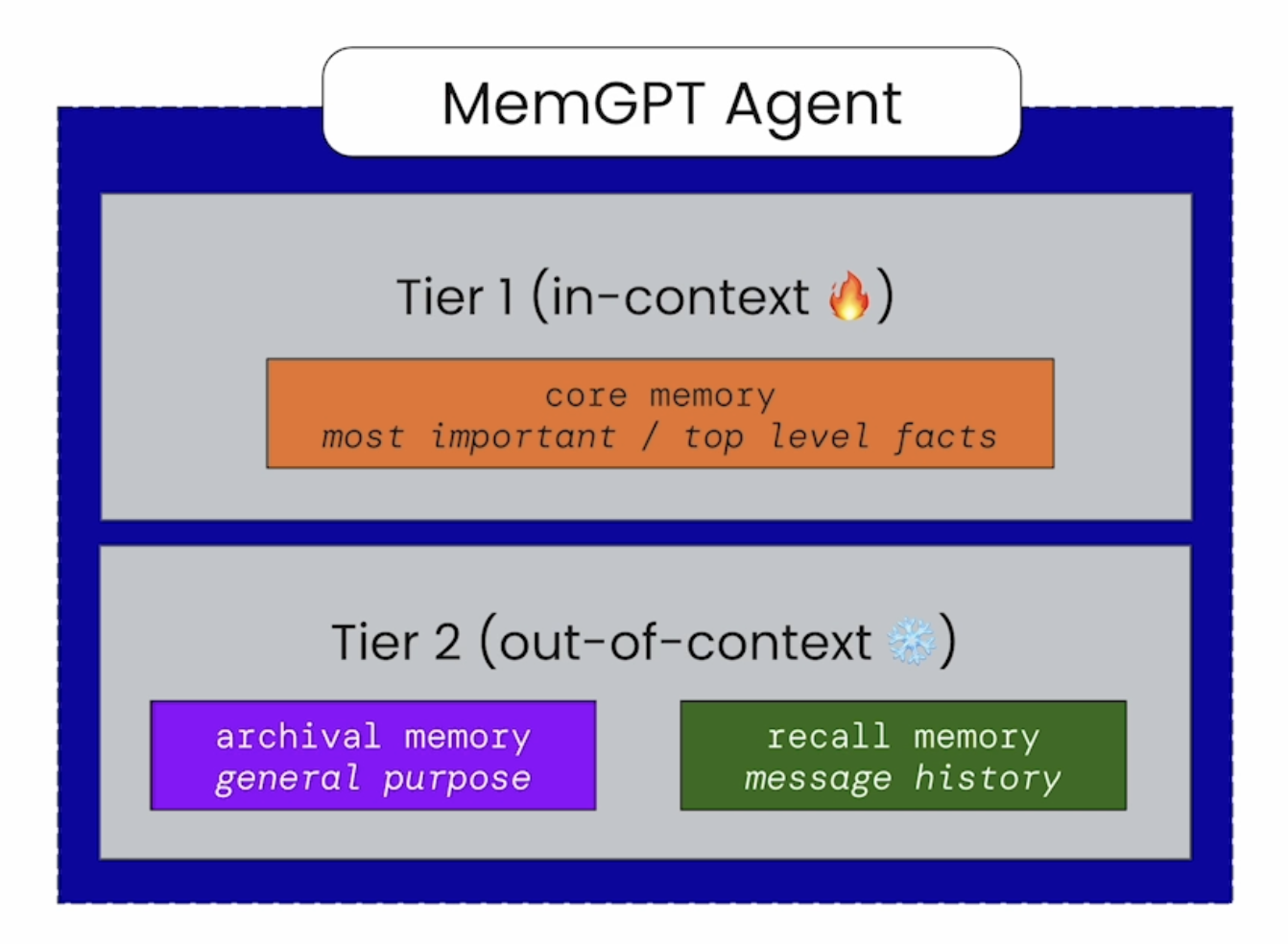
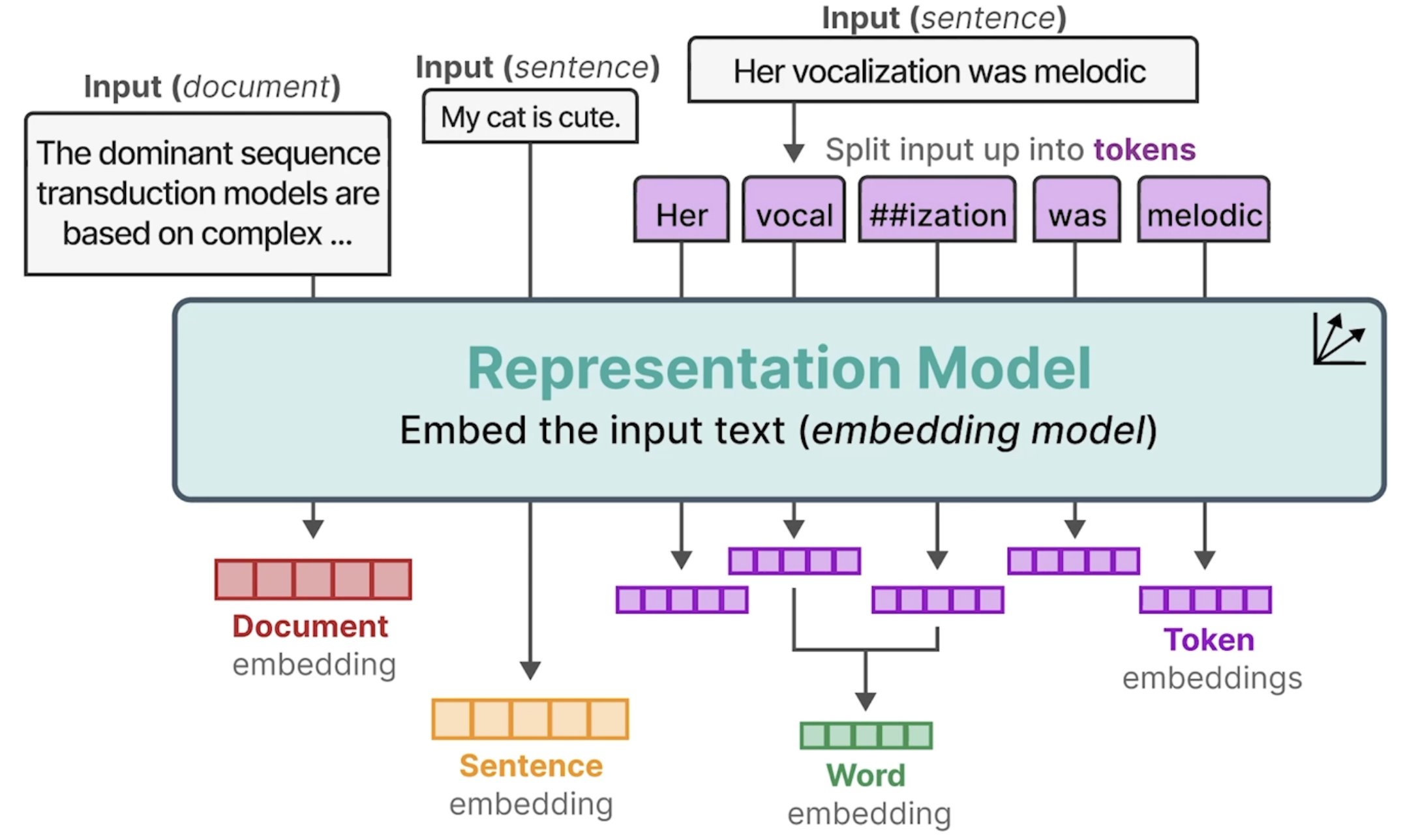
agent_memory = {"human": "", "agent": ""} defcore_memory_save(section: str, memory: str): agent_memory[section] += "\n" agent_memory[section] += memory.strip() print("current memory: ", agent_memory) core_memory_save_desc = """Save important information about you, the agent or the human you are chatting with.""" core_memory_save_propertis = { "section": { "type": "string", "enum": ["human", "agent"], "description": "Must be either 'human'(to save information about the human) \ or 'agent'(to save information about yourself)." }, "memory": { "type": "string", "description": "memory to save in the section." } } # 这里提供了一个 core_memory_save 的 tool core_memory_save_metadata = { "type": "function", "function": { "name": "core_memory_save", "description": core_memory_save_desc, "parameters": { "type": "object", "properties": core_memory_save_propertis, "required": ["section", "memory"] } } }
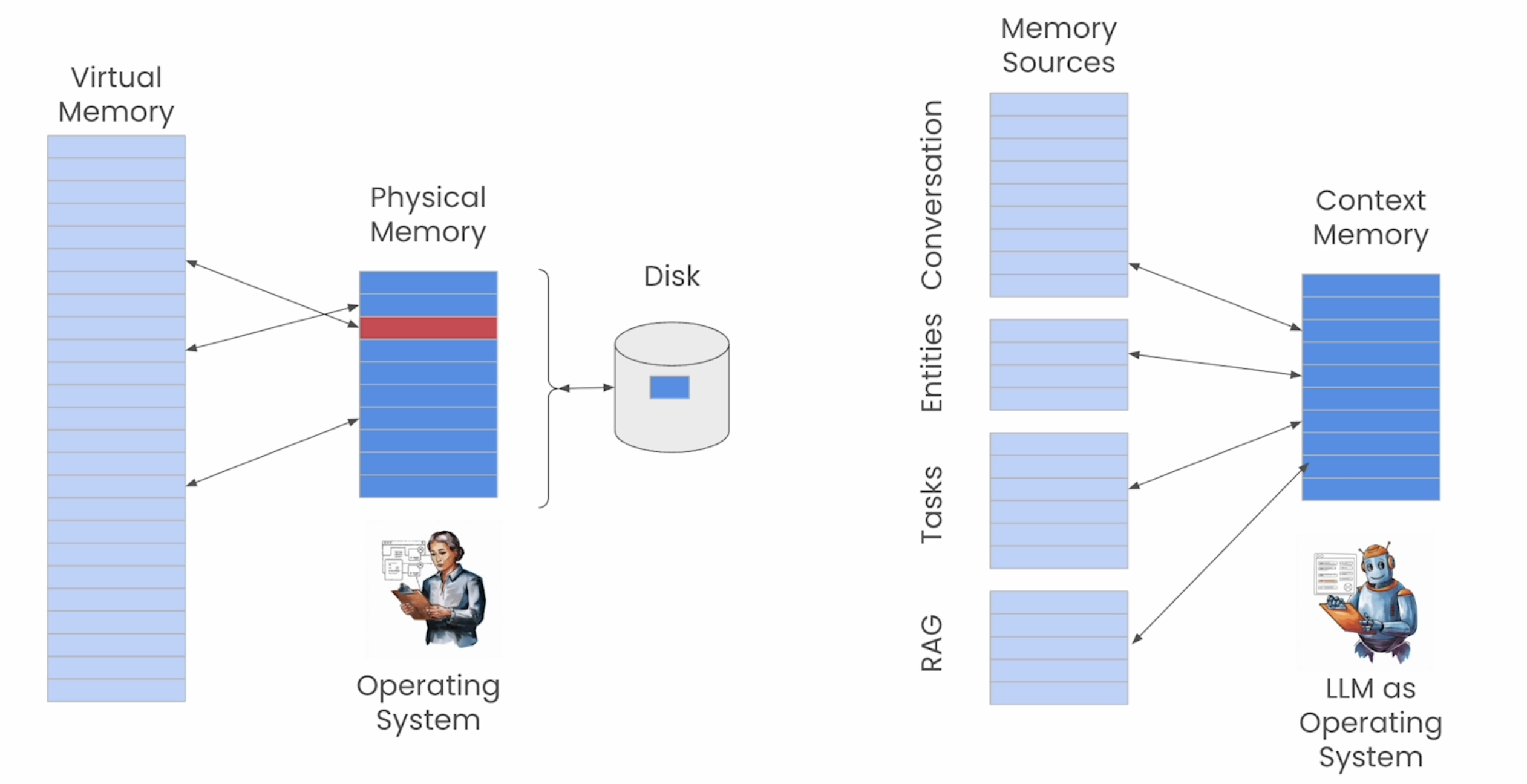
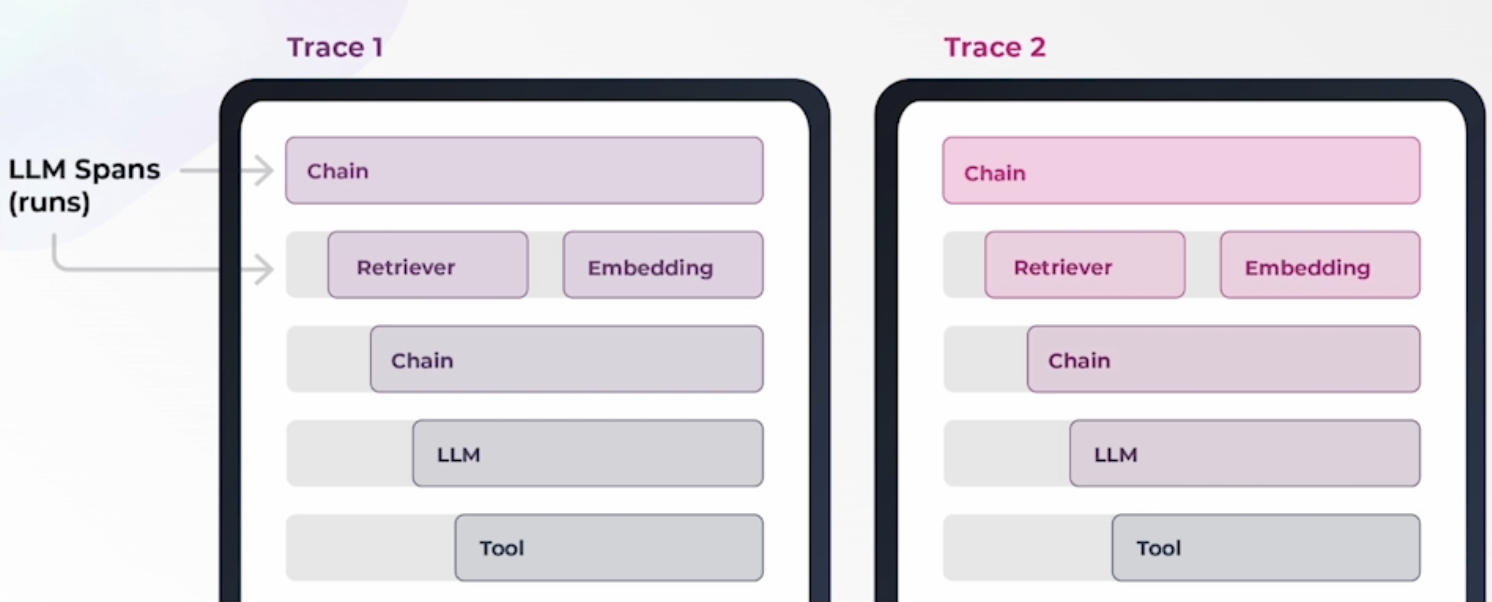
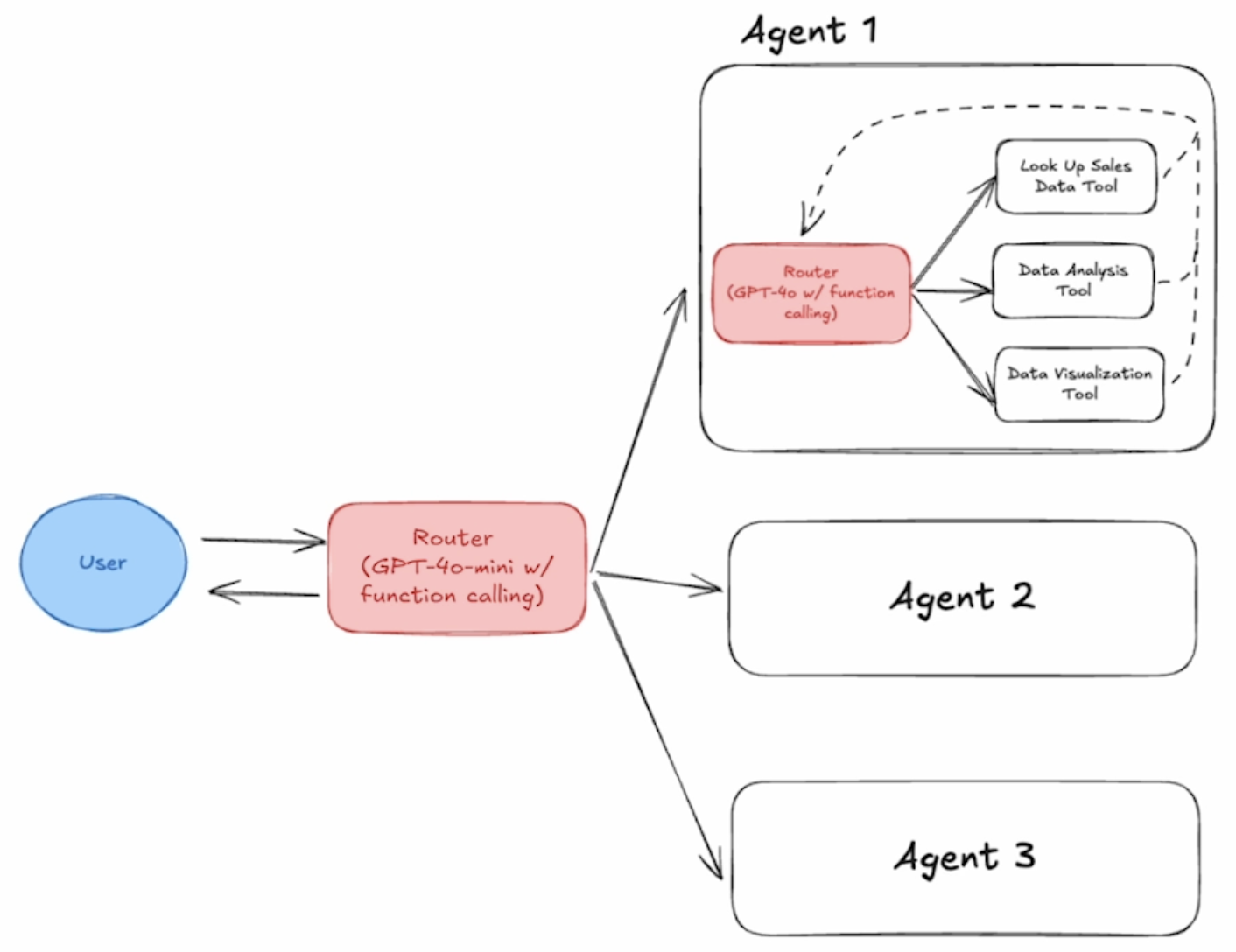
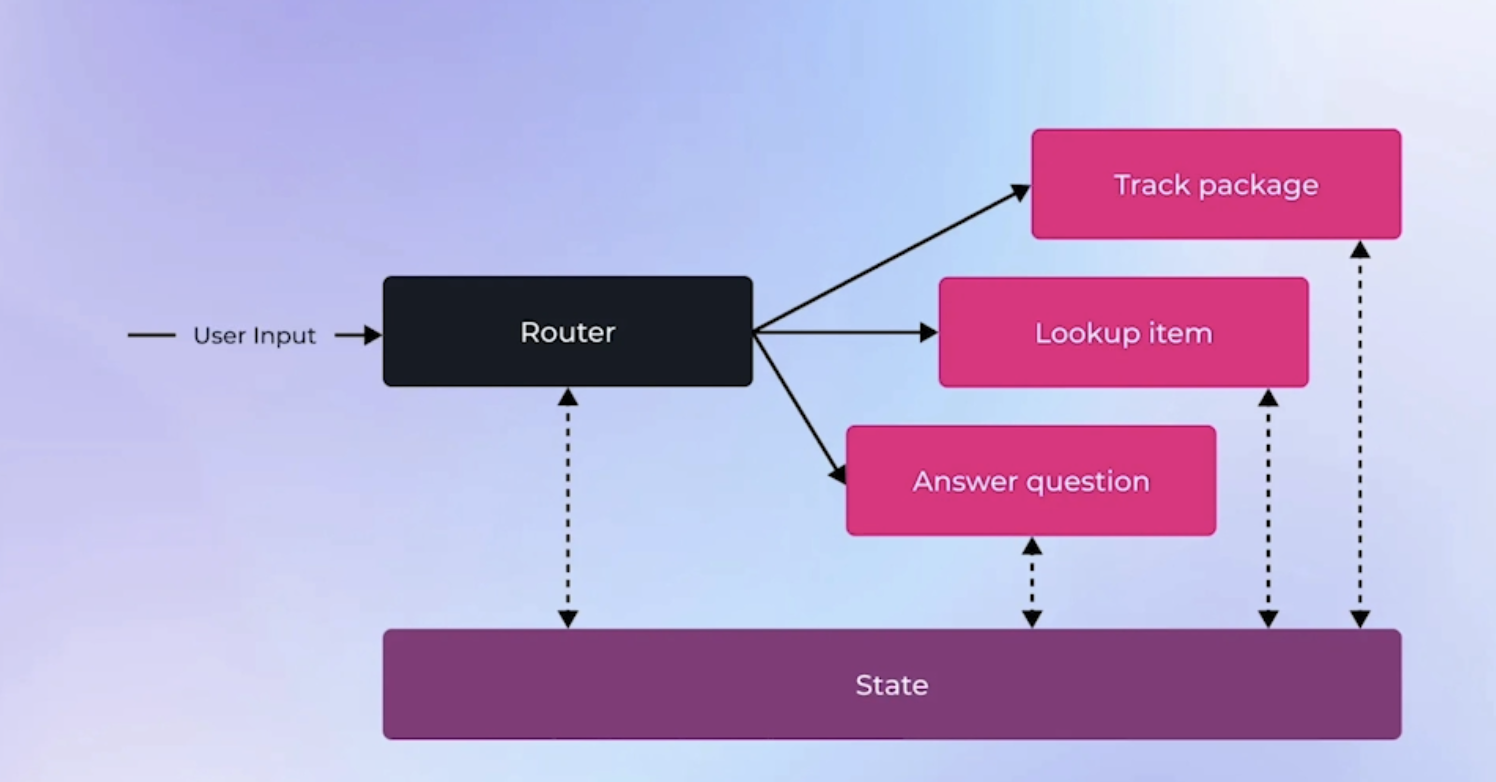
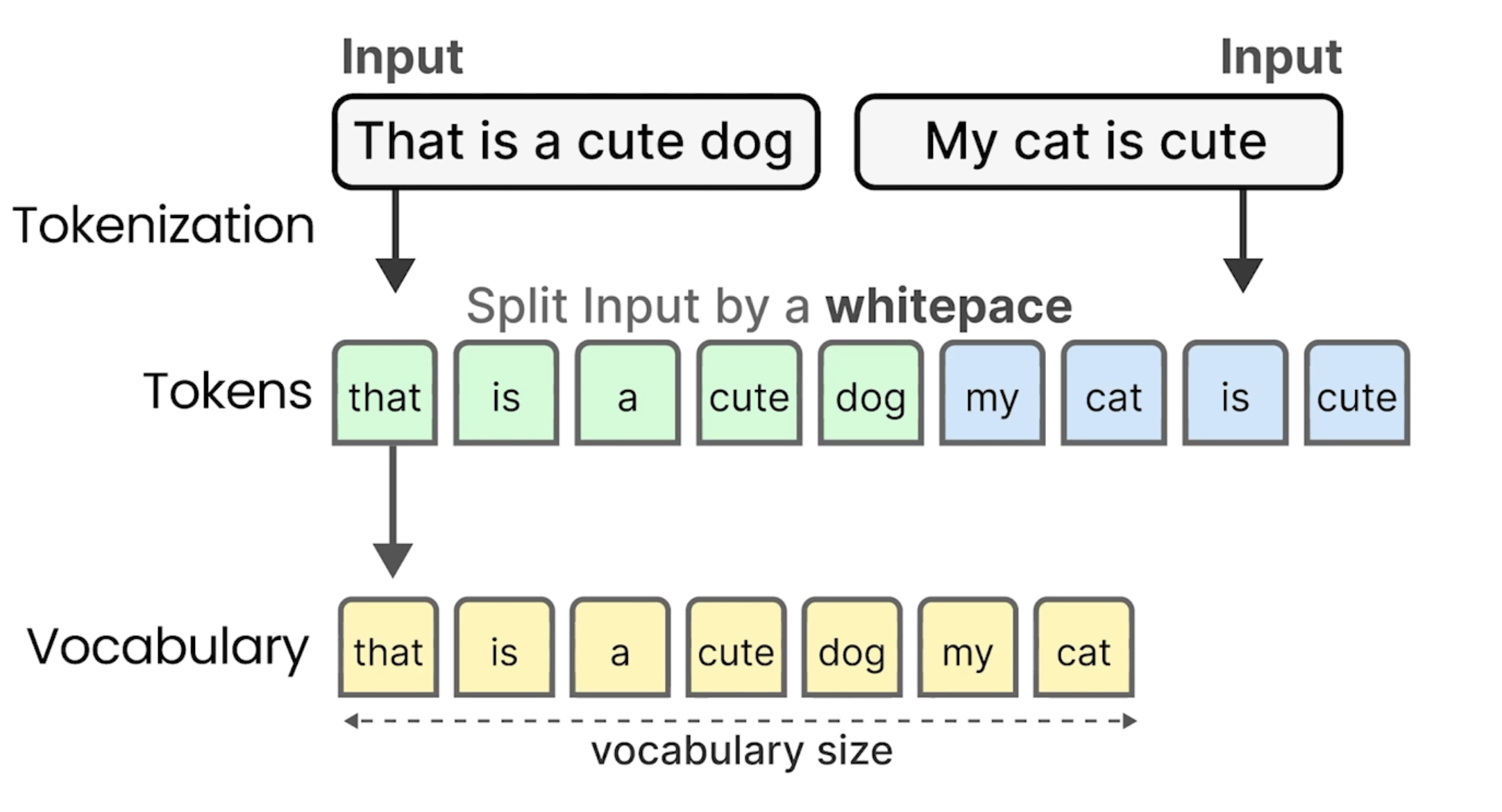
Prompt 设定,提供 Memory Context 管理的能力
1 2 3 4 5 6 7 8 9 10
system_prompt = """you are a chatbot. You have a section of your context called [MEMORY] that contains information relevant to your conversation you can use this information to answer questions. """ messages=[ {"role": "system", "content": system_prompt}, {"role": "system", "content": "[MEMORY]\n" + json.dumps(agent_memory)}, {"role": "user", "content": "My name is QuantumForge"}, ]
Choice(finish_reason='tool_calls', index=0, logprobs=None, message=ChatCompletionMessage(content='\n\n', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_ortft9h7z3gh7l9r6kzt67w6', function=Function(arguments='{"section": "human", "memory": "QuantumForge"}', name='core_memory_save'), type='function')], reasoning_content='Okay, the user mentioned their name is QuantumForge. I need to save that into the core memory under the human section. Let me call the core_memory_save function. The parameters should be section "human" and memory "QuantumForge". Make sure the JSON is correctly formatted.\n')) {'section': 'human', 'memory': 'QuantumForge'} current memory: {'human': 'QuantumForge'}
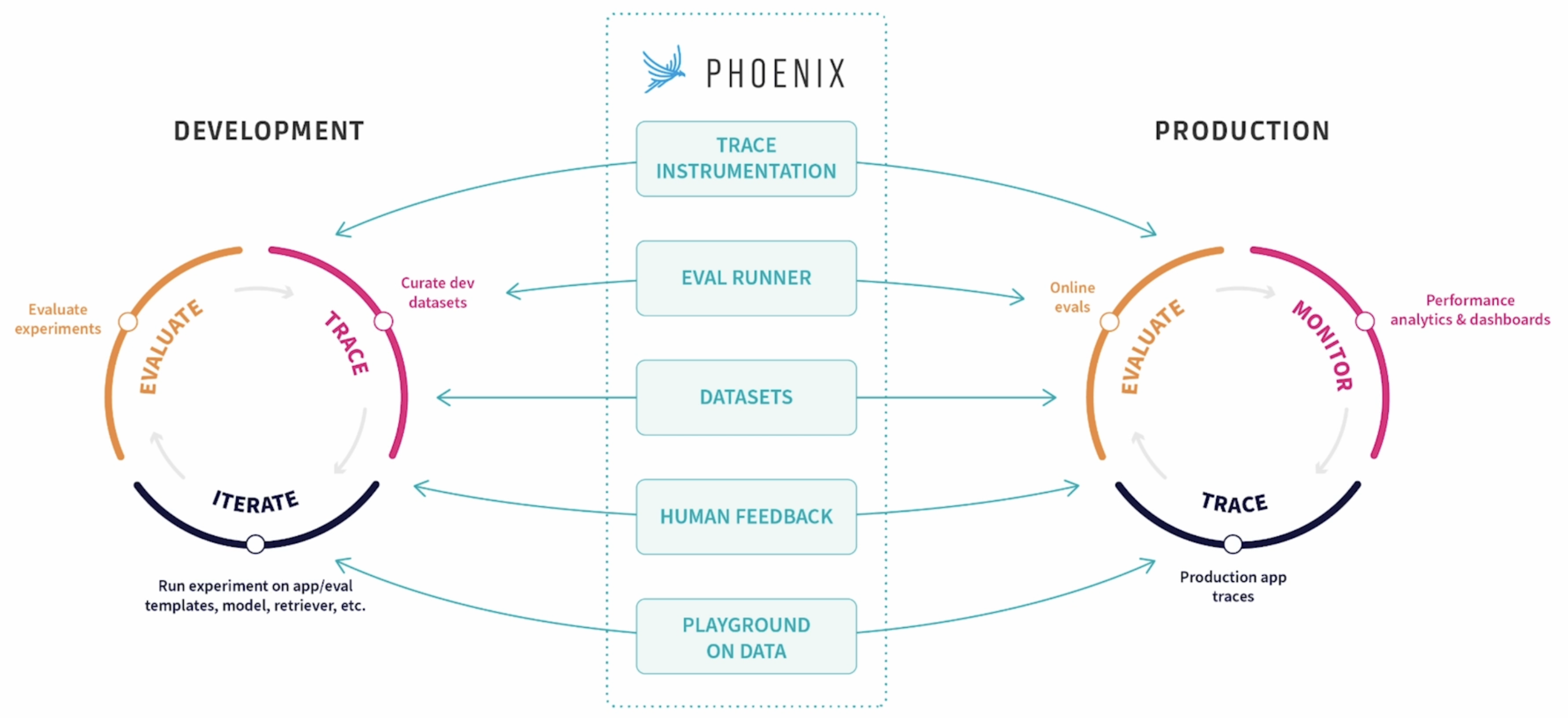
defstart_main_span(messages): print("Starting main span with messages:", messages)
with tracer.start_as_current_span( "AgentRun", openinference_span_kind="agent" ) as span: span.set_input(value=messages) ret = run_agent(messages) print("Main span completed with return value:", ret) span.set_output(value=ret) span.set_status(StatusCode.OK) return ret
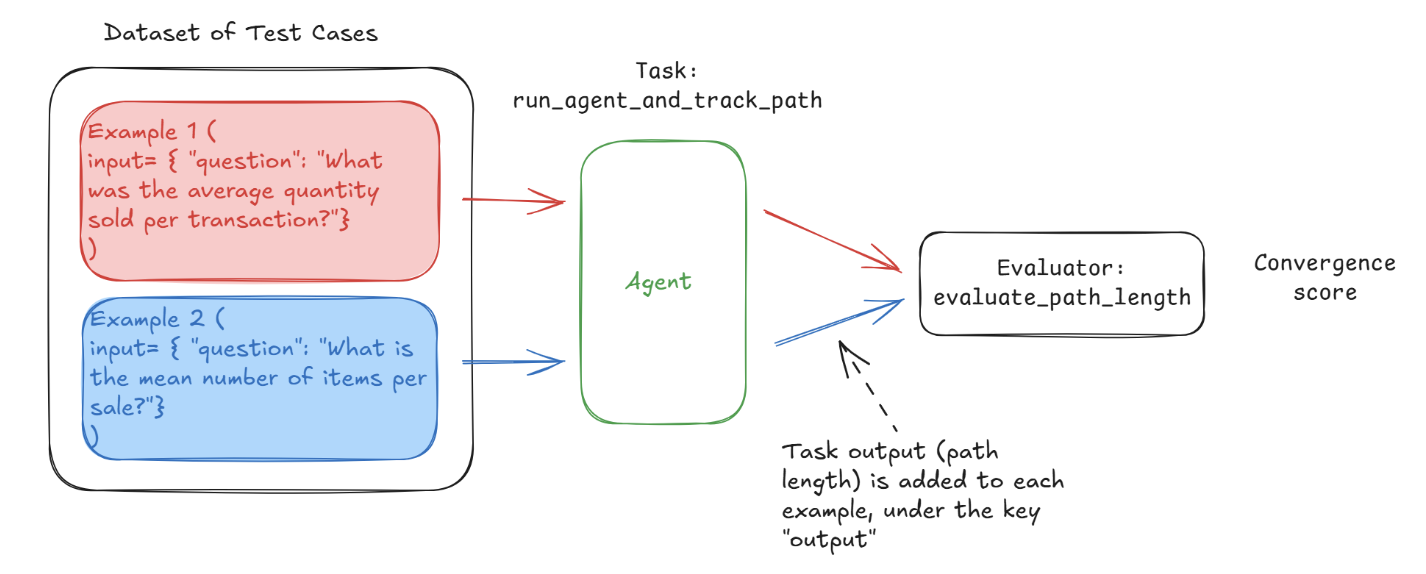
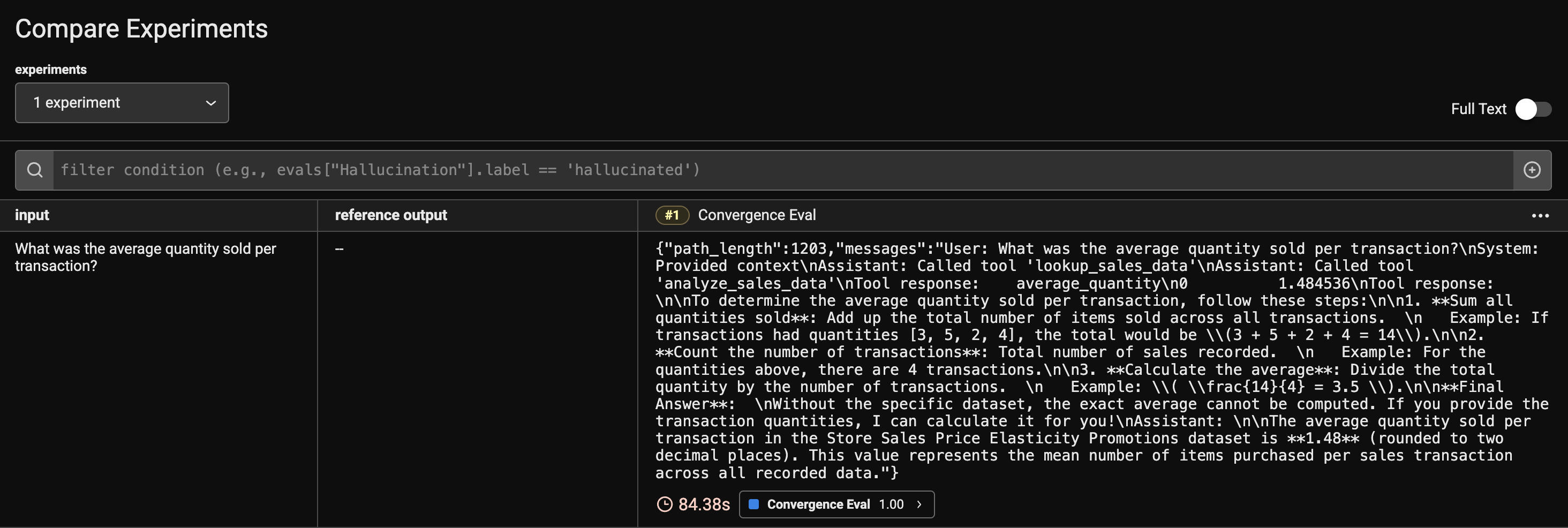
convergence_questions = [ "What was the average quantity sold per transaction?", # ... ] convergence_df = pd.DataFrame({ "question": convergence_questions }) now = datetime.now().strftime("%Y-%m-%d %H:%M:%S") dataset = px_client.upload_dataset(dataframe=convergence_df, dataset_name=f"convergence_questions-{now}", input_keys=["question"])
defformat_message_steps(messages): steps = [] for message in messages: iftype(message) is ChatCompletionMessage: message = message.to_dict() role = message.get("role") if role == "user": steps.append(f"User: {message.get('content')}") elif role == "system": steps.append("System: Provided context") elif role == "assistant": if message.get("tool_calls"): for tool_call in message["tool_calls"]: tool_name = tool_call["function"]["name"] steps.append(f"Assistant: Called tool '{tool_name}'") else: steps.append(f"Assistant: {message.get('content')}") elif role == "tool": steps.append(f"Tool response: {message.get('content')}") return"\n".join(steps)
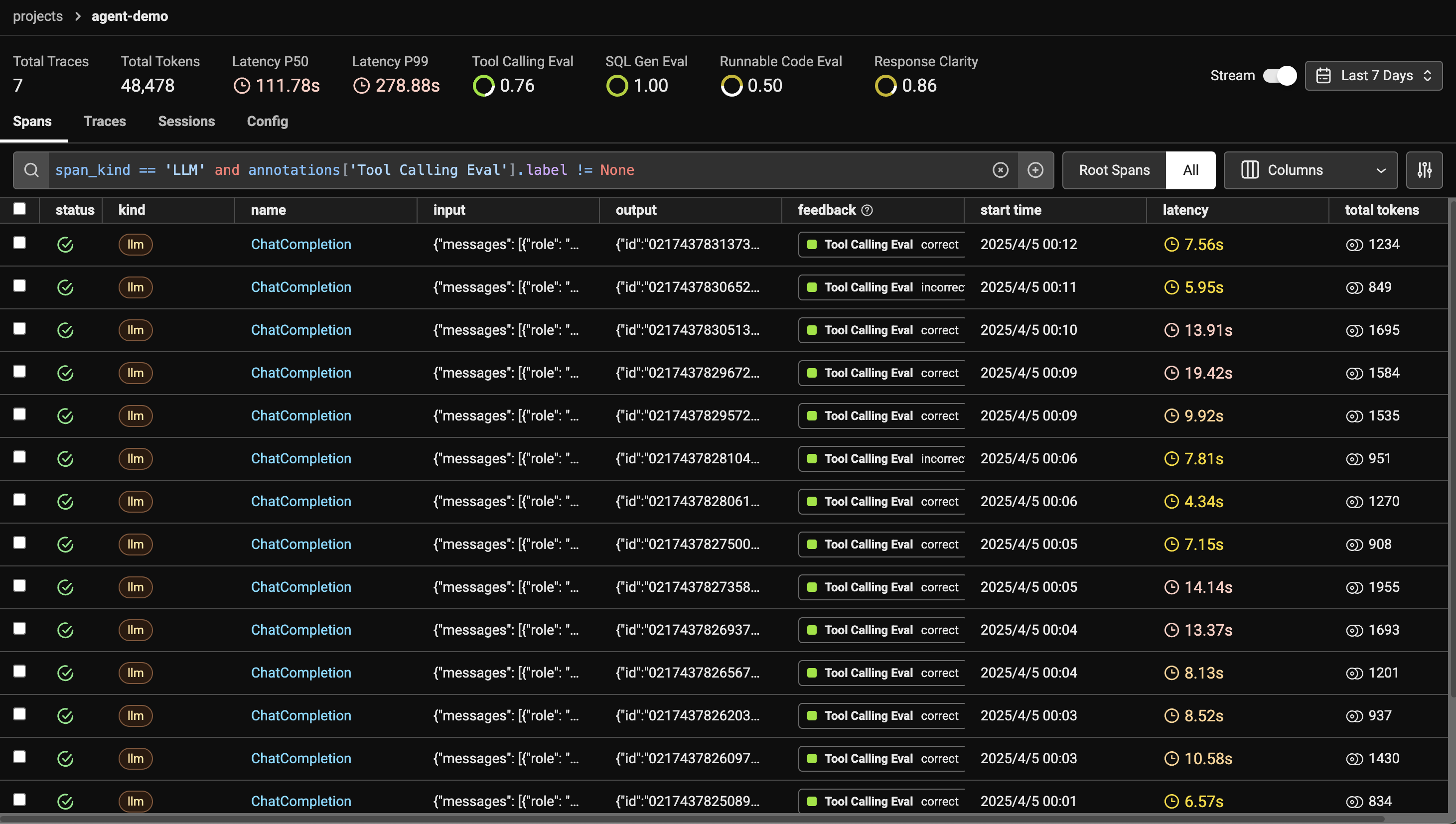
experiment = run_experiment(dataset, run_agent_and_track_path, experiment_name="Convergence Eval", experiment_description="Evaluating the convergence of the agent") outputs = experiment.as_dataframe()["output"].to_dict().values()
optimal_path_length = min(output.get('path_length') for output in outputs \ if output and output.get('path_length') isnotNone) print(f"The optimal path length is {optimal_path_length}")
@create_evaluator(name="Convergence Eval", kind="CODE") defevaluate_path_length(output: str) -> float: if output and output.get("path_length"): return optimal_path_length/float(output.get("path_length")) else: return0 experiment = evaluate_experiment(experiment, evaluators=[evaluate_path_length]) print(experiment.as_dataframe())
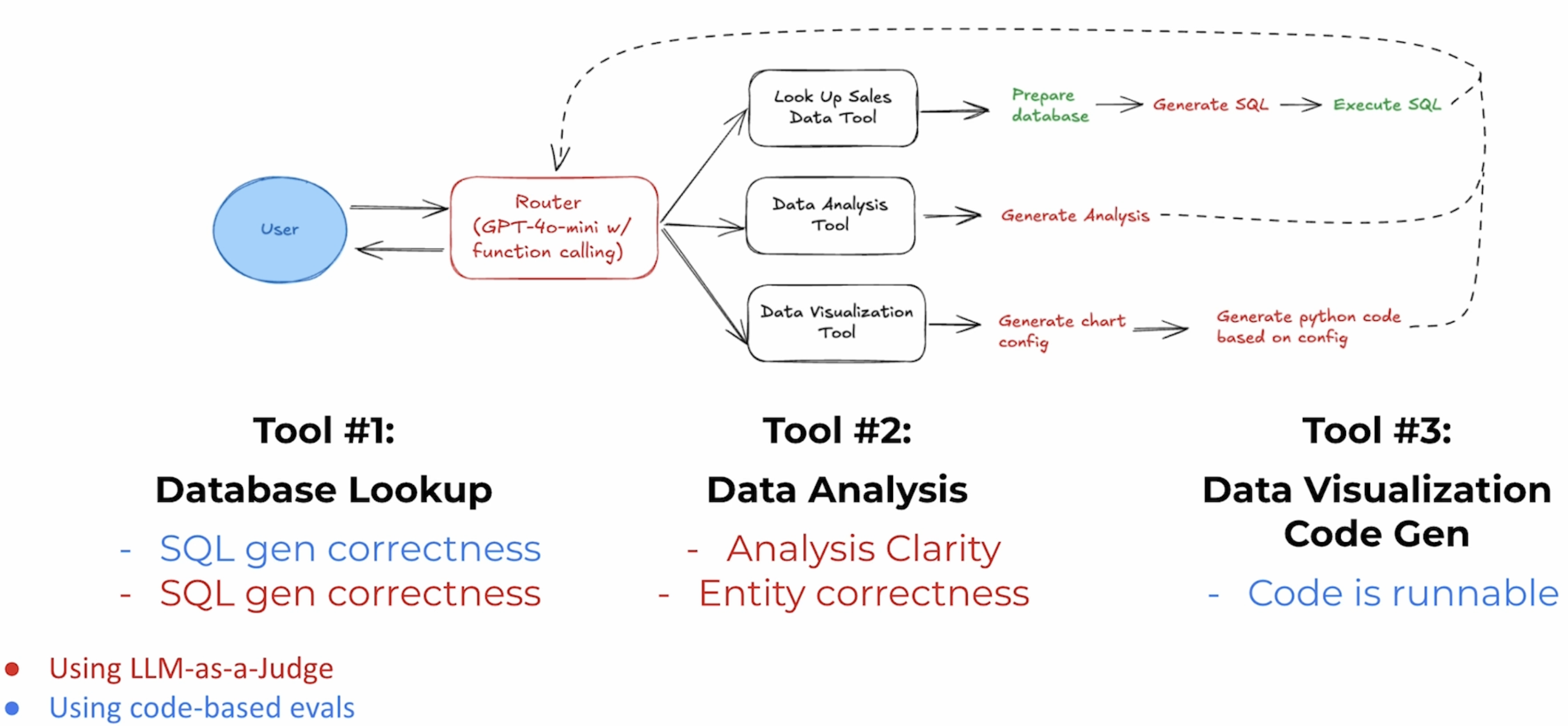
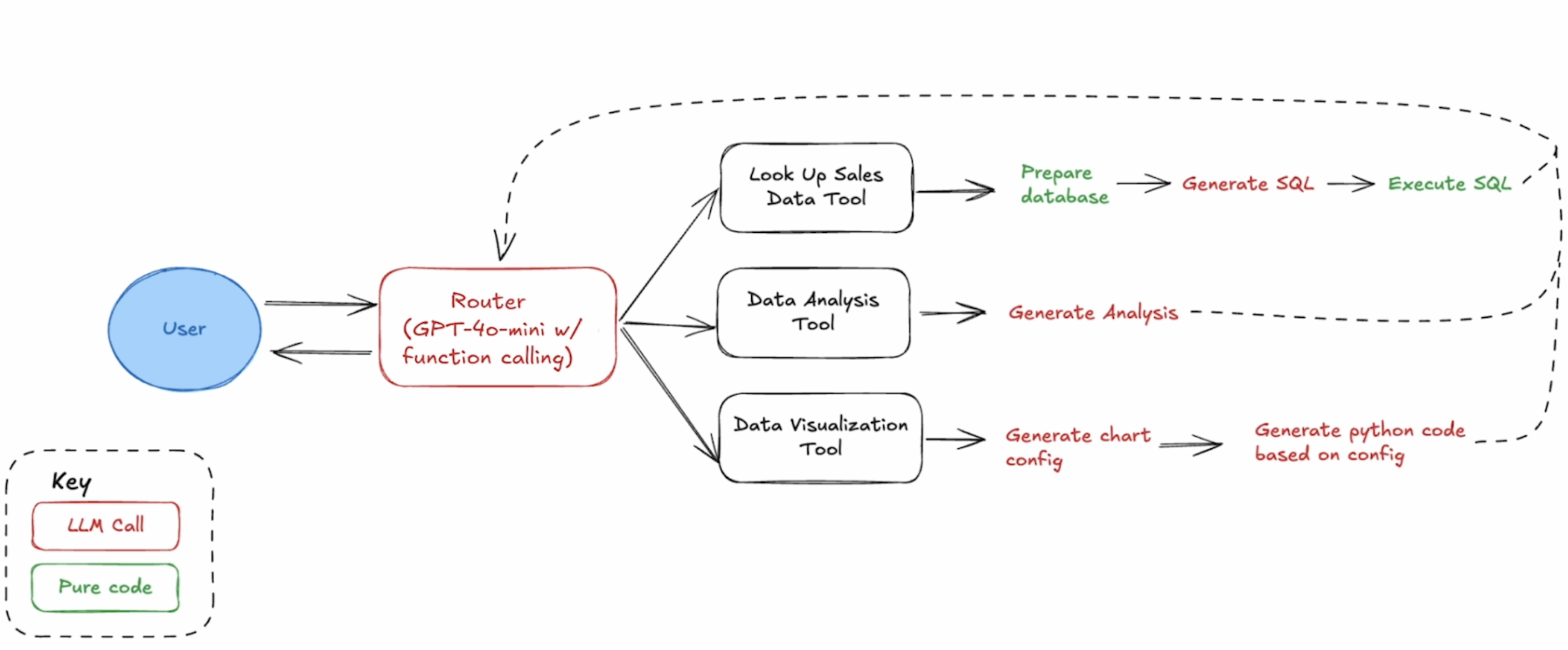
# SQL 查询语句升成的 prompt 模板 SQL_GENERATION_PROMPT = """ Generate an SQL query based on a prompt. Do not reply with anything besides the SQL query. The prompt is: {prompt} The available columns are: {columns} The table name is: {table_name} Limit returned rows to 20. """ defgenerate_sql_query(prompt: str, columns: list, table_name: str) -> str: """Generate an SQL query based on a prompt""" formatted_prompt = SQL_GENERATION_PROMPT.format(prompt=prompt, columns=columns, table_name=table_name) return query_model(formatted_prompt)
TRANSACTION_DATA_FILE_PATH = './Store_Sales_Price_Elasticity_Promotions_Data.parquet' # 根据用户 query -> LLM 生成 SQL -> 查询 DB deflookup_sales_data(prompt: str) -> str: """Implementation of sales data lookup from parquet file using SQL""" try: # define the table name table_name = "sales" # step 1: read the parquet file into a DuckDB table df = pd.read_parquet(TRANSACTION_DATA_FILE_PATH) duckdb.sql(f"CREATE TABLE IF NOT EXISTS {table_name} AS SELECT * FROM df") # step 2: generate the SQL code sql_query = generate_sql_query(prompt, df.columns, table_name) # clean the response to make sure it only includes the SQL code sql_query = sql_query.strip() sql_query = sql_query.replace("```sql", "").replace("```", "") # step 3: execute the SQL query result = duckdb.sql(sql_query).df()
return result.to_string() except Exception as e: returnf"Error accessing data: {str(e)}"
用模型来分析数据
用上一步查询到的数据,让模型分析给出 Insight。
1 2 3 4 5 6 7 8 9 10 11
# 数据分析的 Prompt 模板 DATA_ANALYSIS_PROMPT = """ Analyze the following data: {data} Your job is to answer the following question: {prompt} """ defanalyze_sales_data(prompt: str, data: str) -> str: """Implementation of AI-powered sales data analysis""" formatted_prompt = DATA_ANALYSIS_PROMPT.format(data=data, prompt=prompt) analysis = query_model(formatted_prompt)
return analysis if analysis else"No analysis could be generated"
# 生成 Chart 配置的 Prompt 模板 CHART_CONFIGURATION_PROMPT = """ Generate a chart configuration based on this data: {data} The goal is to show: {visualization_goal} Return the chart configuration as a JSON object with the following keys: - chart_type: Type of chart to generate - x_axis: Name of the x-axis column - y_axis: Name of the y-axis column - title: Title of the chart Only return the JSON object, no other text. """ classVisualizationConfig(BaseModel): chart_type: str = Field(..., description="Type of chart to generate") x_axis: str = Field(..., description="Name of the x-axis column") y_axis: str = Field(..., description="Name of the y-axis column") title: str = Field(..., description="Title of the chart") defextract_chart_config(data: str, visualization_goal: str) -> dict: """Generate chart visualization configuration Args: data: String containing the data to visualize visualization_goal: Description of what the visualization should show Returns: Dictionary containing line chart configuration """ formatted_prompt = CHART_CONFIGURATION_PROMPT.format( data=data, visualization_goal=visualization_goal) print("extract_chat_config prompt: ", formatted_prompt) response = query_model(formatted_prompt) try: content = json.loads(response) return { "chart_type": content.chart_type, "x_axis": content.x_axis, "y_axis": content.y_axis, "title": content.title, "data": data } except Exception: return { "chart_type": "line", "x_axis": "date", "y_axis": "value", "title": visualization_goal, "data": data }
生成画图的 Python 代码
根据上一步给出的 Chart 配置,生成 Python 画图代码,输出进行一些简单的处理,保留 raw 代码。
# 生成画图 Python 代码的 Prompt 模板 CREATE_CHART_PROMPT = """ Write python code to create a chart based on the following configuration. Only return the code, no other text. config: {config} """ defcreate_chart(config: dict) -> str: """Create a chart based on the configuration""" formatted_prompt = CREATE_CHART_PROMPT.format(config=config)
defgenerate_visualization(data: str, visualization_goal: str) -> str: """Generate a visualization based on the data and goal""" config = extract_chart_config(data, visualization_goal) code = create_chart(config) return code
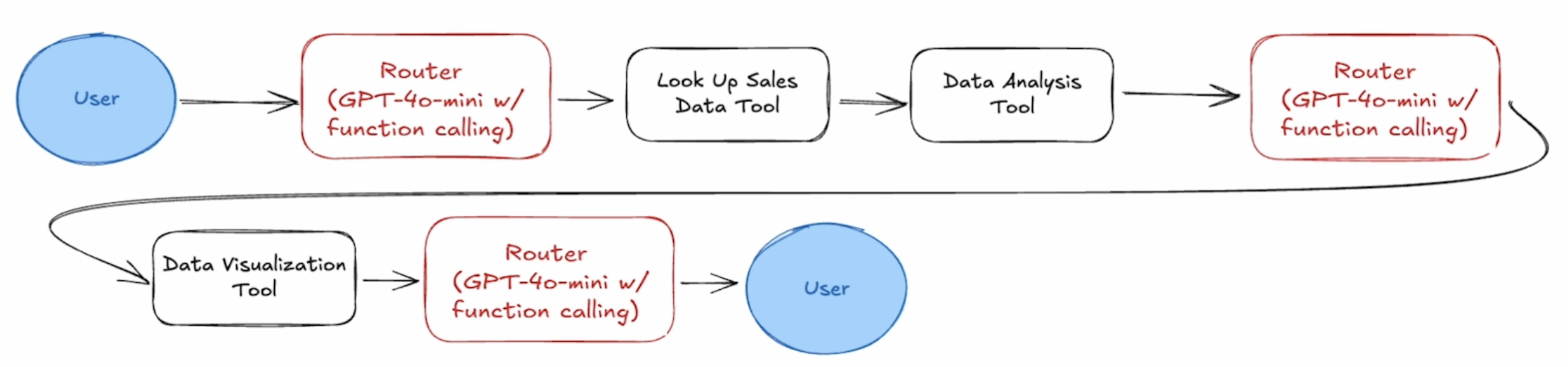
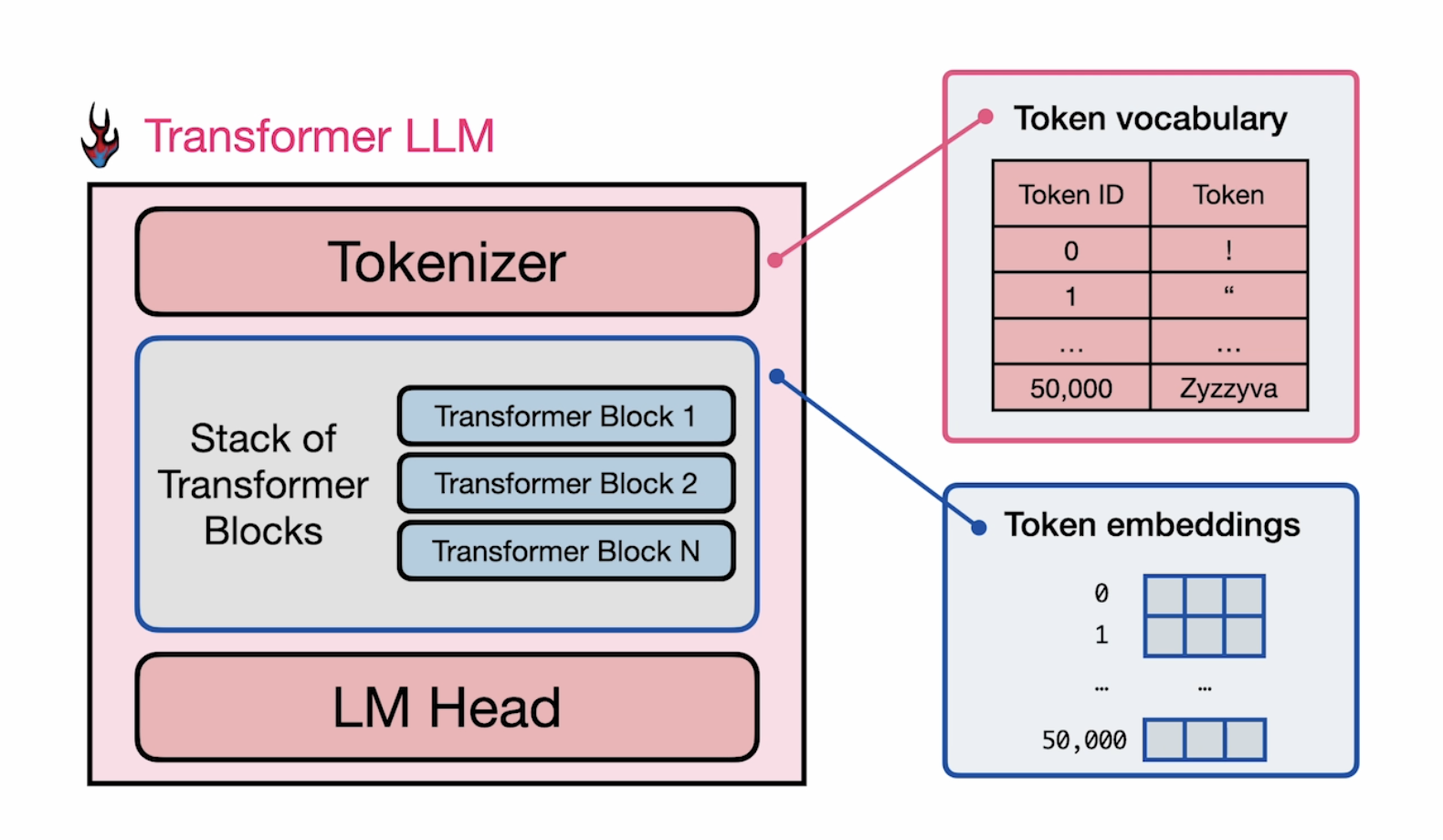
SYSTEM_PROMPT = """ You are a helpful assistant that can answer questions about the Store Sales Price Elasticity Promotions dataset. """ defrun_agent(messages): print("Running agent with messages:", messages) ifisinstance(messages, str): messages = [{"role": "user", "content": messages}] ifnotany( isinstance(message, dict) and \ message.get("role") == "system"for message in messages ): system_prompt = {"role": "system", "content": SYSTEM_PROMPT} messages.append(system_prompt)
# if the model decides to call function(s), call handle_tool_calls if tool_calls: print("Processing tool calls") messages = handle_tool_calls(tool_calls, messages) else: print("No tool calls, returning final response") return response.choices[0].message.content
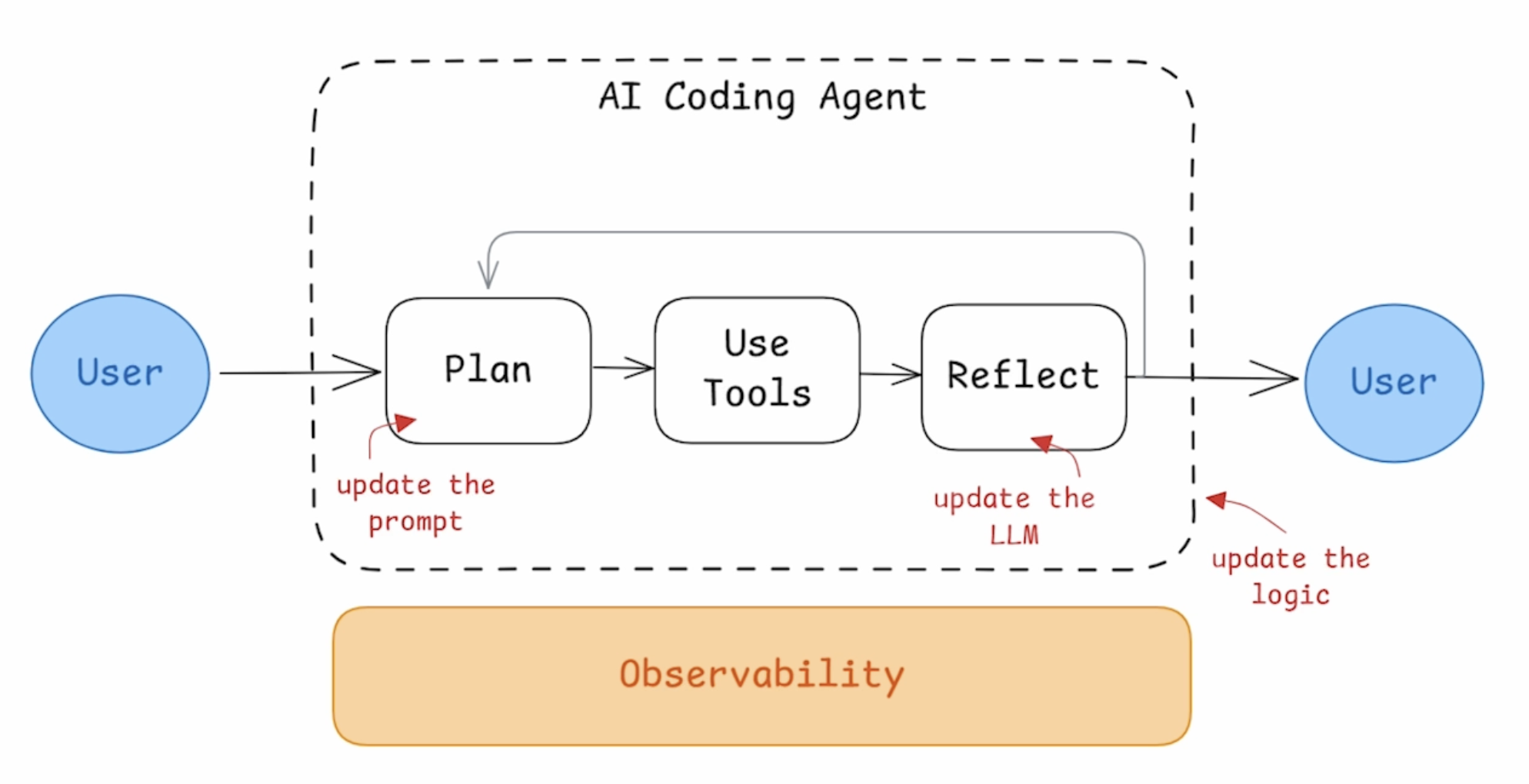
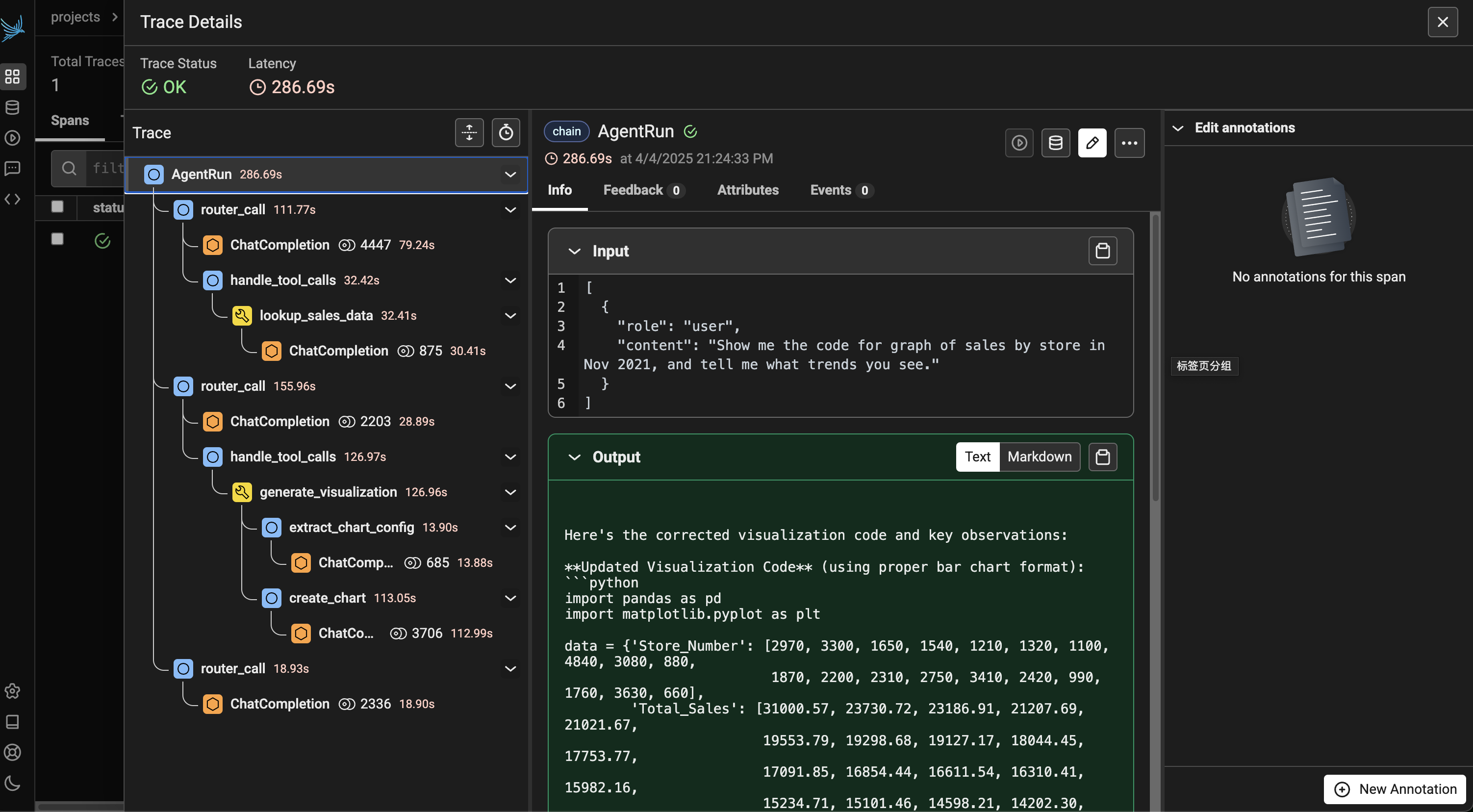
执行 Agent 逻辑
执行 Agent 主逻辑:
1 2
result = run_agent('Show me the code for graph of sales by store in Nov 2021, and tell me what trends you see.') print(result)
1. **Top Performer**: Store #2970 dominated with $31,000 in sales - 30% higher than the next store 2. **Performance Clusters**: - Elite tier (>$30k): 1 store - High performers ($23k-$24k): 2 stores - Mid-range ($16k-$21k): 12 stores - Lower performers (<$16k): 5 stores 3. **No Size Pattern**: Store numbers don't correlate with sales performance (e.g., Store #660 is low despite small number) 4. **$10k Spread**: Difference between top and bottom stores exceeds $18,000 5. **Promotion Effectiveness**: The wide variance suggests different promotional execution or customer response across locations
Recommendation: Focus analysis on Store #2970's successful strategies and investigate operational factors in lower-performing stores (#660, #1760, #3630).
# A list of colors in RGB for representing the tokens colors = [ '102;194;165', '252;141;98', '141;160;203', '231;138;195', '166;216;84', '255;217;47' ]
defshow_tokens(sentence: str, tokenizer_name: str): """ Show the tokens each separated by a different color """
# Load the tokenizer and tokenize the input tokenizer = AutoTokenizer.from_pretrained(tokenizer_name) token_ids = tokenizer(sentence).input_ids
# Print a colored list of tokens for idx, t inenumerate(token_ids): print( f'\x1b[0;30;48;2;{colors[idx % len(colors)]}m' + tokenizer.decode(t) + '\x1b[0m', end=' ' )
sentence = """ English and CAPITALIZATION 🎵 鸟 show_tokens False None elif == >= else: two tabs:" " Three tabs: " " 12.0*50=600 """ show_tokens(sentence, "bert-base-cased") show_tokens(sentence, "Xenova/gpt-4") show_tokens(sentence, "Qwen/Qwen2-VL-7B-Instruct")
Python 代码输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Vocab length: 28996 [CLS] English and CA ##PI ##TA ##L ##I ##Z ##AT ##ION [UNK] [UNK] show _ token ##s F ##als ##e None el ##if = = > = else : two ta ##bs : " " Three ta ##bs : " " 12 . 0 * 50 = 600 [SEP]
Vocab length: 100263 English and CAPITAL IZATION � � � � � � show _tokens False None elif == >= else : two tabs :" " Three tabs : " " 12 . 0 * 50 = 600
Vocab length: 151657 English and CAPITAL IZATION 🎵 � � � show _tokens False None elif == >= else : two tabs :" " Three tabs : " " 1 2 . 0 * 5 0 = 6 0 0
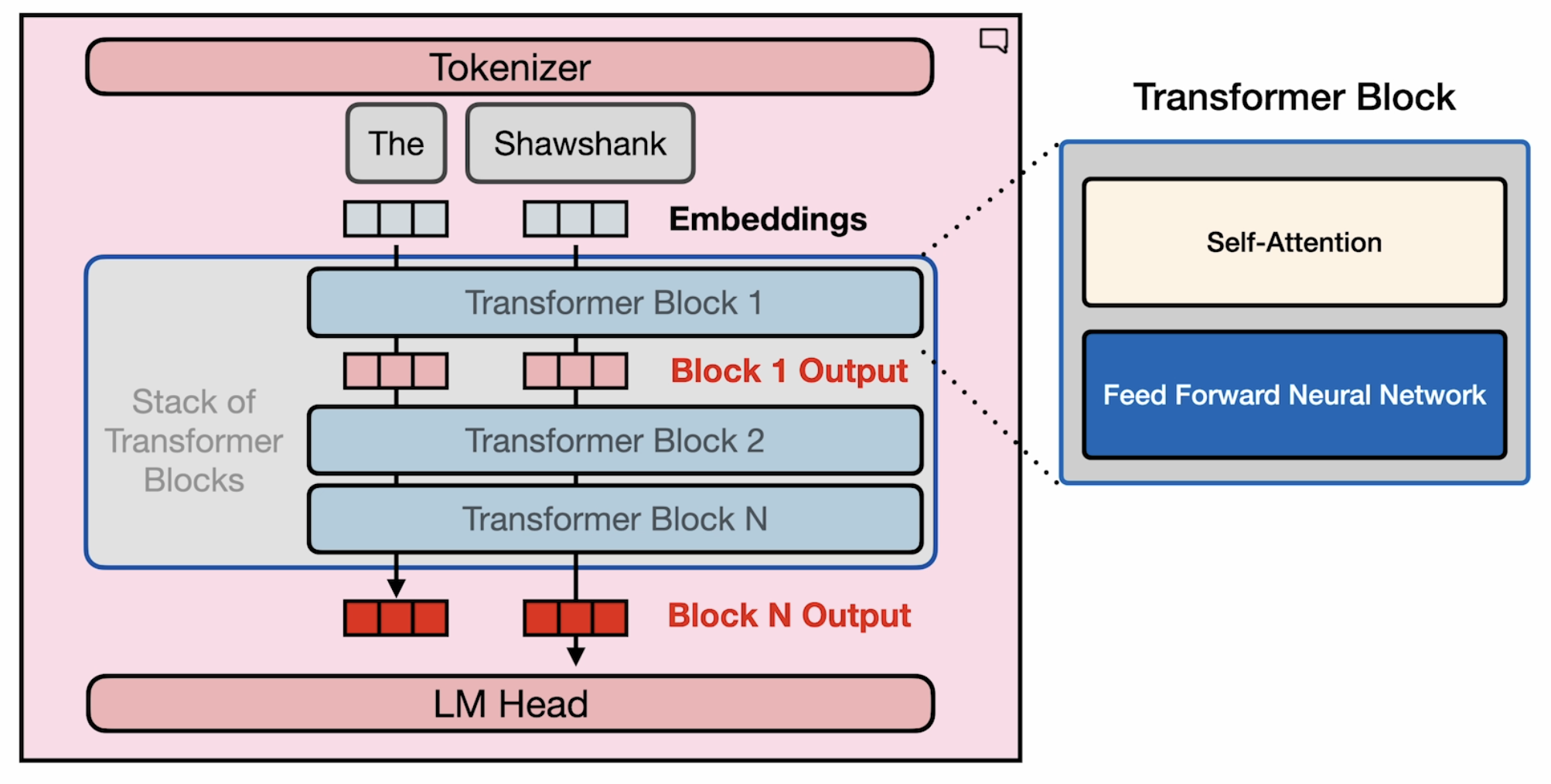
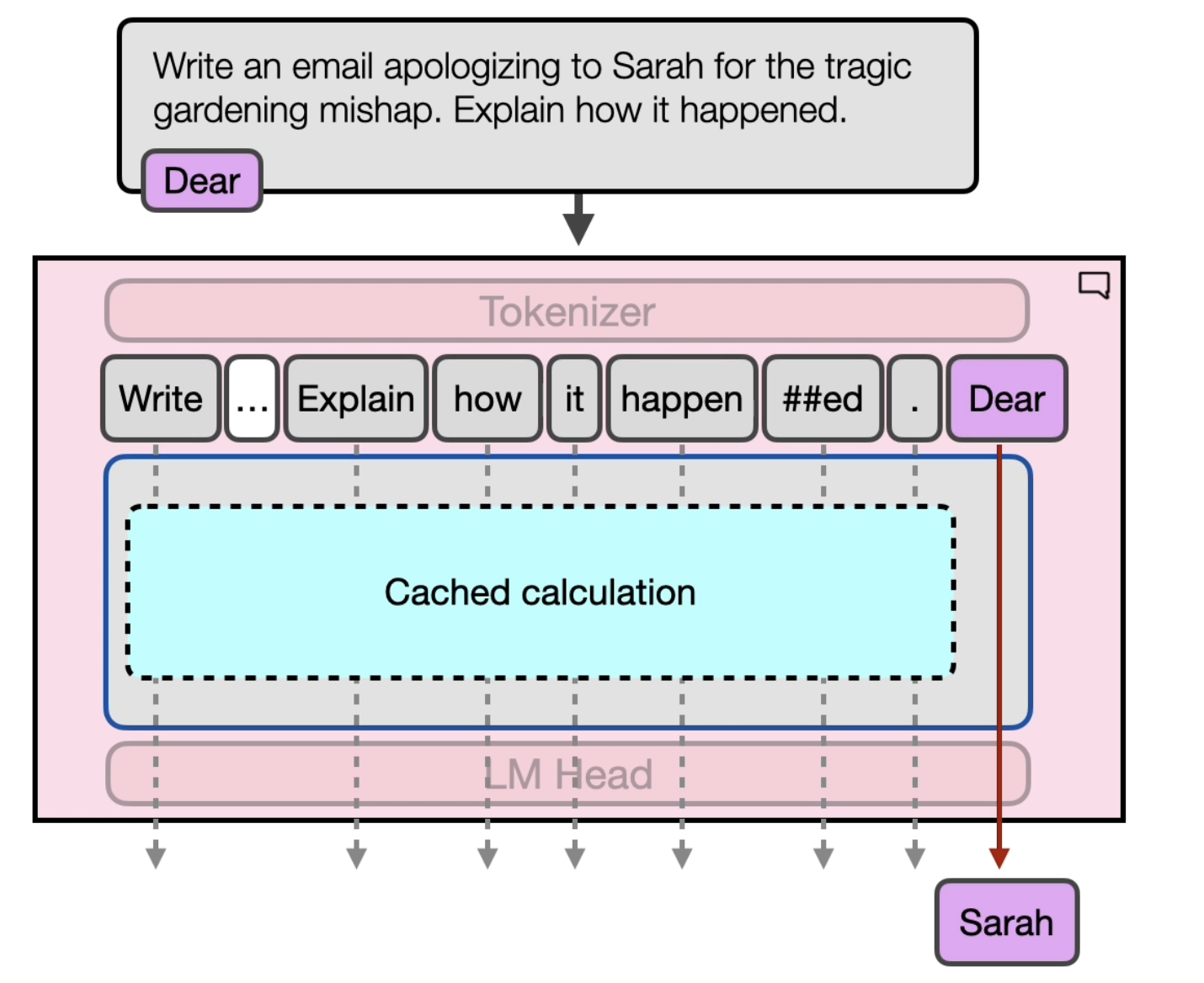
prompt = "Write an email apologizing to Sarah for the tragic gardening mishap. Explain how it happened. " output = generator(prompt) print(output[0]['generated_text'])
输出文本:
1 2 3 4 5 6 7 8 9
Email to Sarah:
Subject: Sincere Apologies for the Gardening Mishap
Dear Sarah,
I hope this message finds you well. I am writing to express my deepest ap
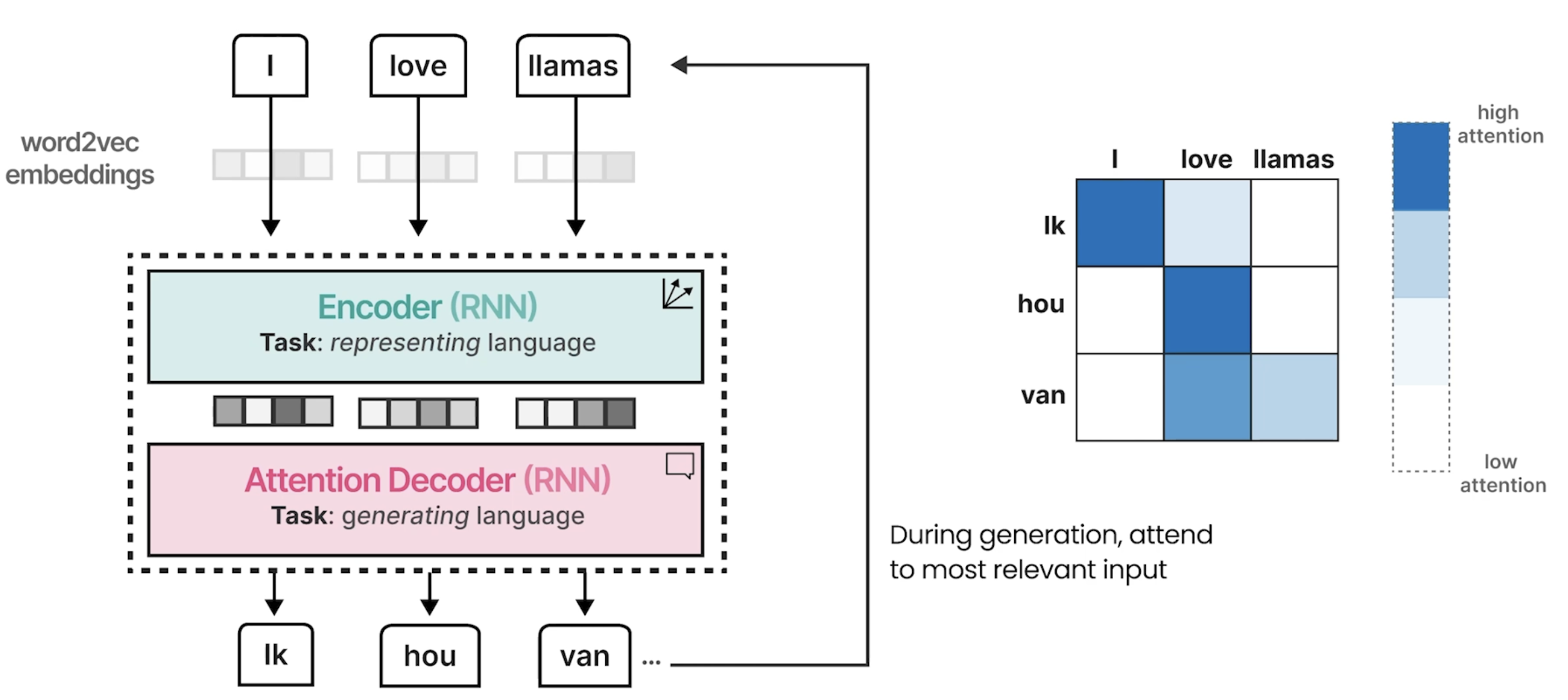
基于 Prompt 生成单个单词:
1 2 3 4 5 6 7 8 9
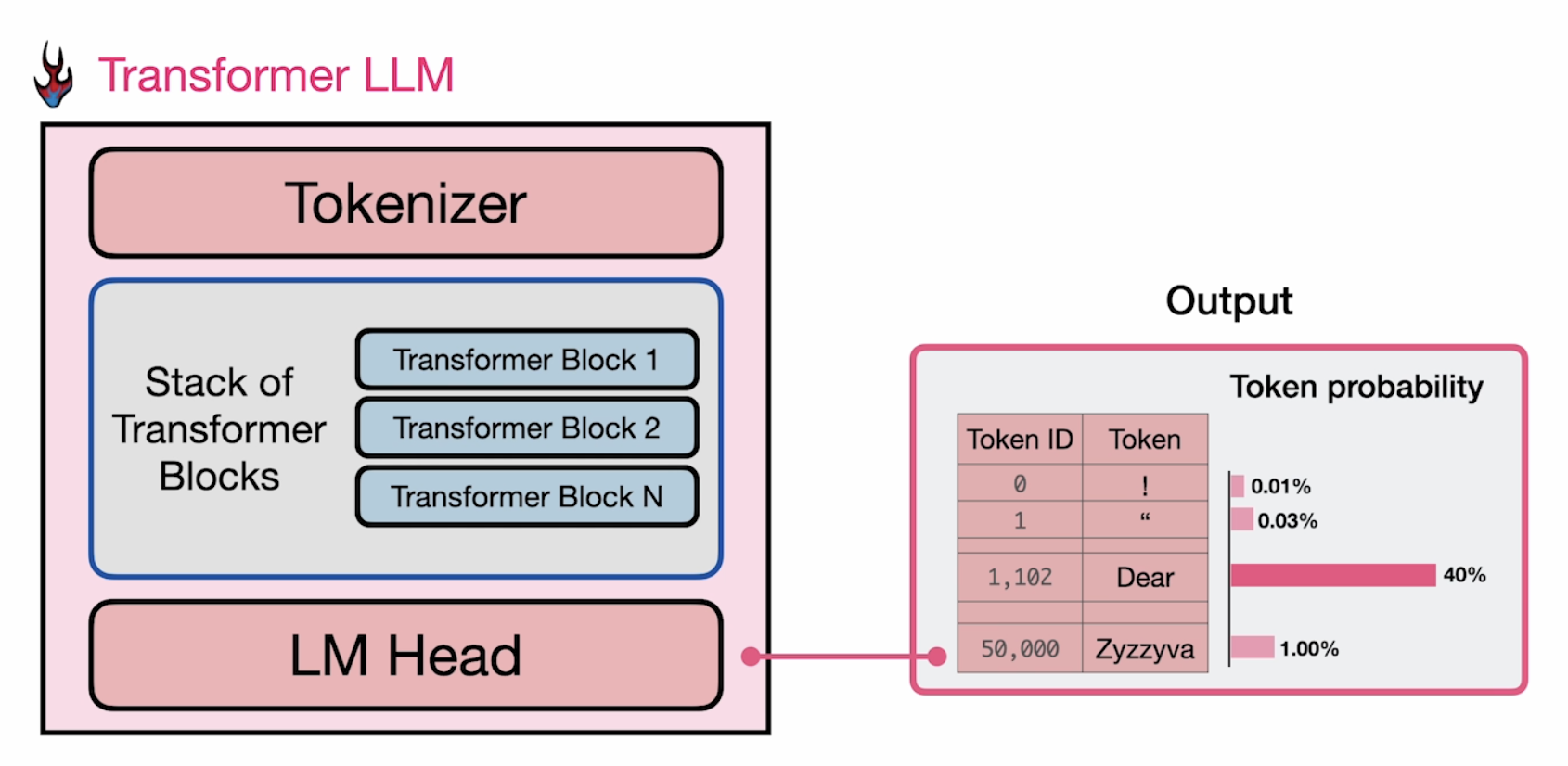
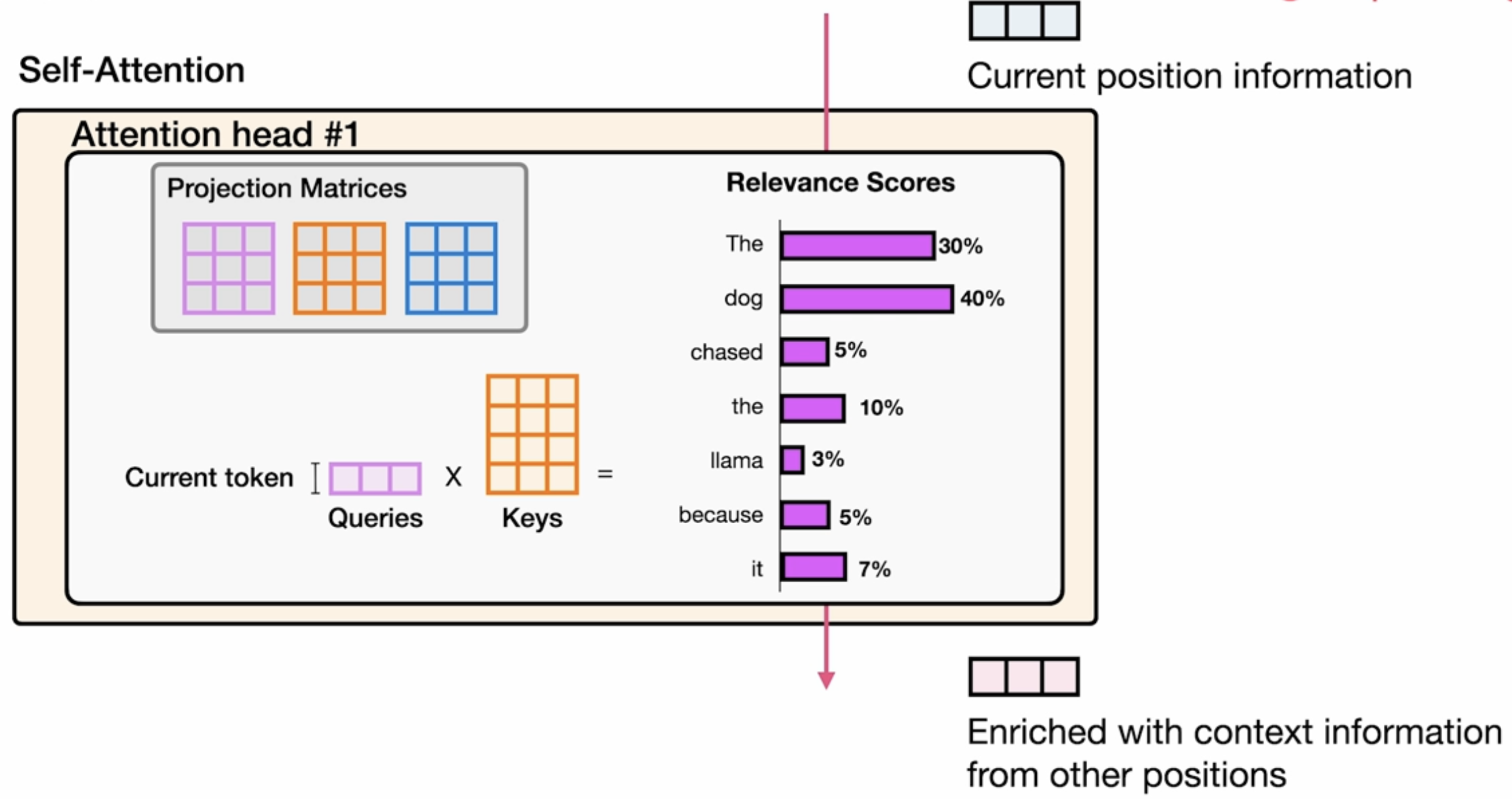
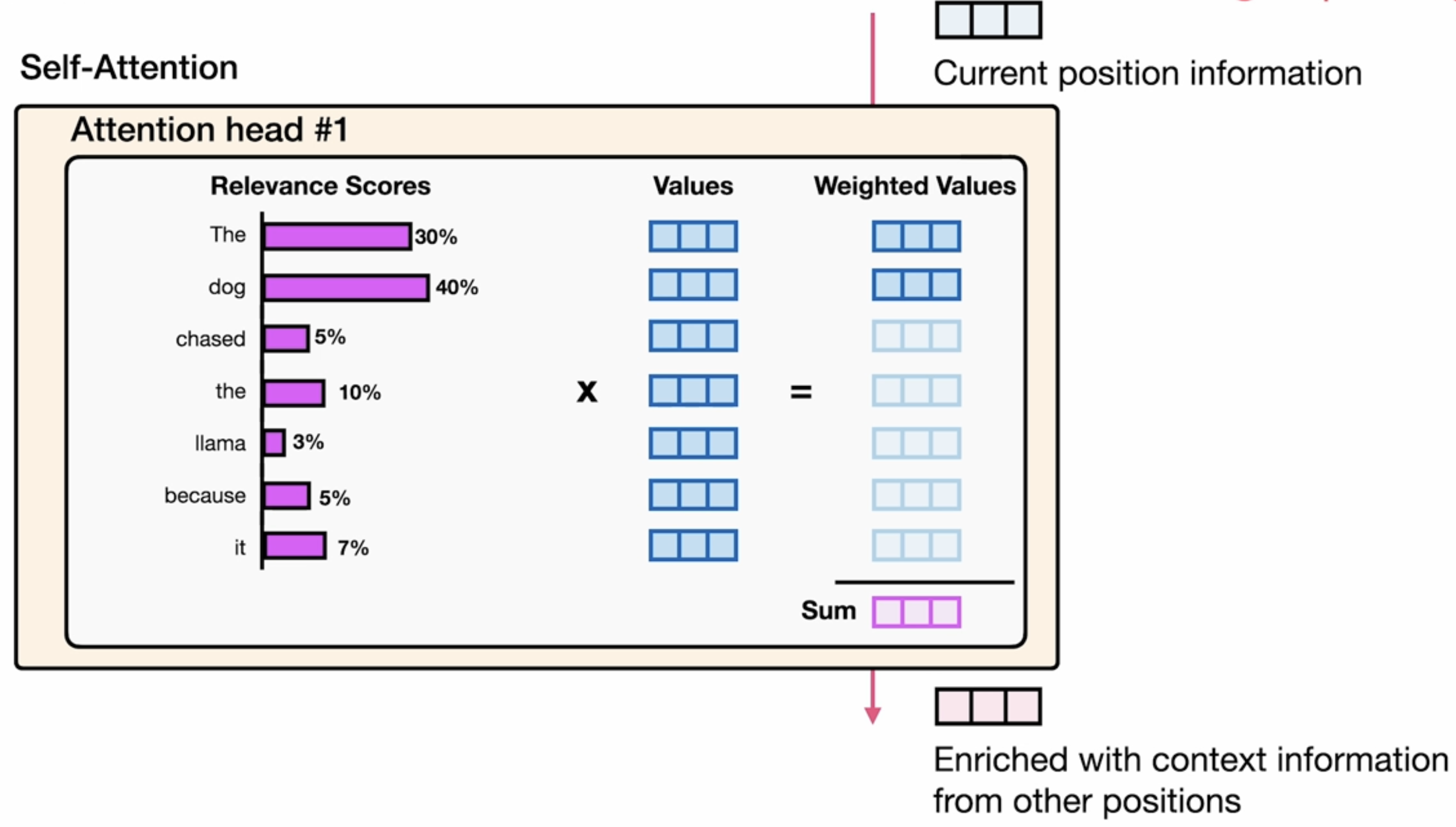
prompt = "The capital of France is" # Tokenize the input prompt input_ids = tokenizer(prompt, return_tensors="pt").input_ids # Get the output of the model before the lm_head model_output = model.model(input_ids) # Get the output of the lm_head lm_head_output = model.lm_head(model_output[0]) token_id = lm_head_output[0,-1].argmax(-1) tokenizer.decode(token_id)