【Agents 开发】如何为 Agent 增加 Memory 能力
详细阅读:https://www.letta.com/research
内容笔记:来自 deeplearning.ai 「LLMs as Operating Systems: Agent Memory」
在和 LLM 模型交互过程中,输入的 Prompt(也叫做 Input Context)能够很大程序上影响模型的推理和输出结果,基于 Prompt + LLM 调用默认是没有持久化 Memory 能力,用户需要显式去管理必要的上下文存储。在 Agent 应用过程中,可能需要做记忆的内容包括:
- 和用户的聊天历史
- 用户身份相关的信息
- 任务历史
- Multi-Agent 系统共享信息
LLM 的 Input Context Window 是有限的,更长的 Context Window 推理消耗的资源和延时都会更大,如何管理 in-context 信息哪些要被包含进 context Window,哪些不包含,在需要去关注的问题。
《MemGPT: Towards LLMs as Operating Systems》这片论文提出了如何管理 Agent Memory 的方法,这里把 Memory Sources vs. Context Memory(实际 LLM 推理中用到的 Context),类比在 操作系统里面的 Virtual Memory vs. Physical Memory。
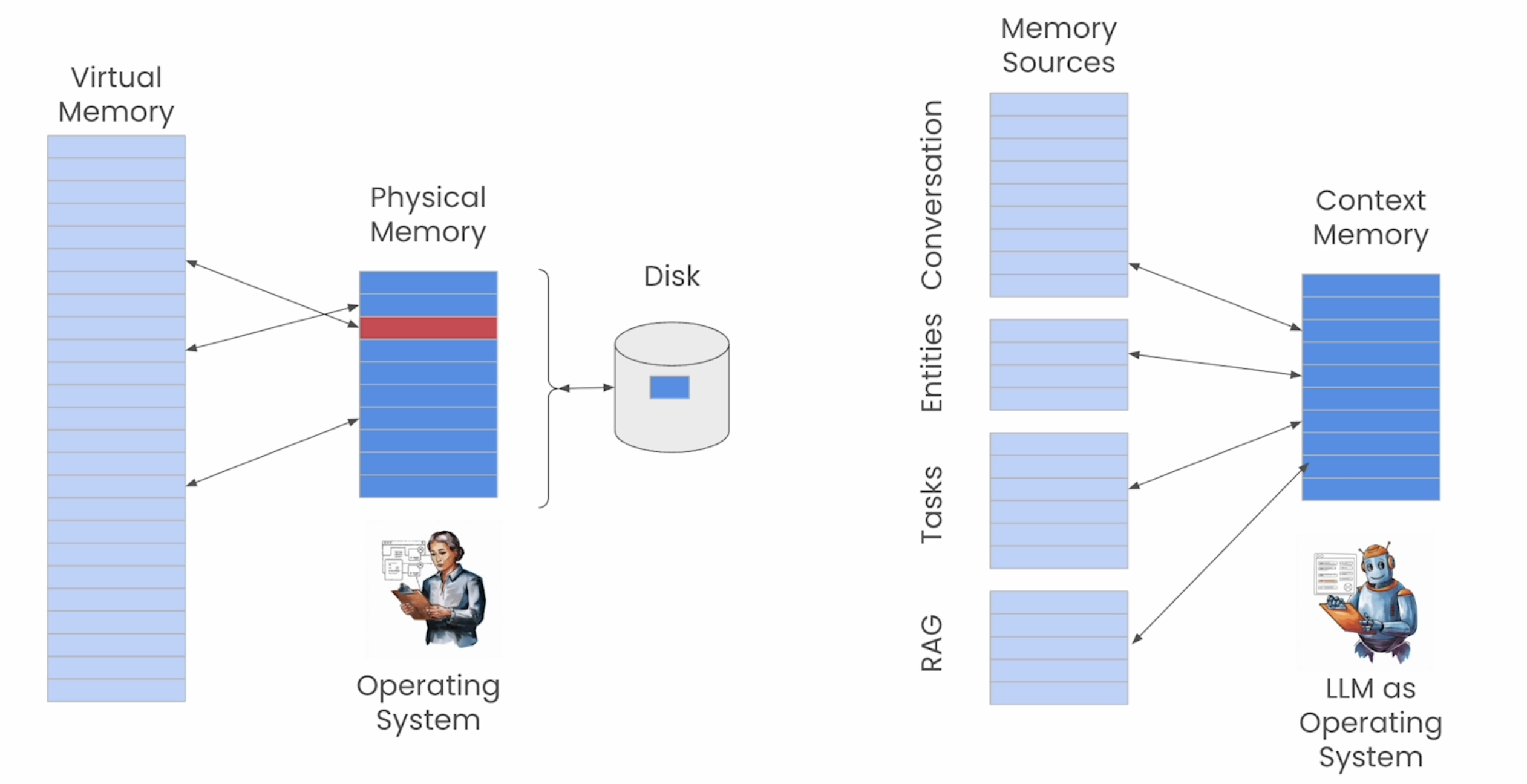
Agents 内存读写
基于 LLM 多轮推理的 Agents,需要在推理过程中维护一个 State 数据。多轮推理的过程称为 Agentic Loop,单次的推理(对应一次 LLM call)称为 agent step,在一个 agent step 中:
- 从 Agent State 中加载上下文,拼接到 LLM Context Window,这个过程称为 Context compilation
- 基于输入的 Context Window 做 LLM 推理
- LLM 输出更新 Agent State
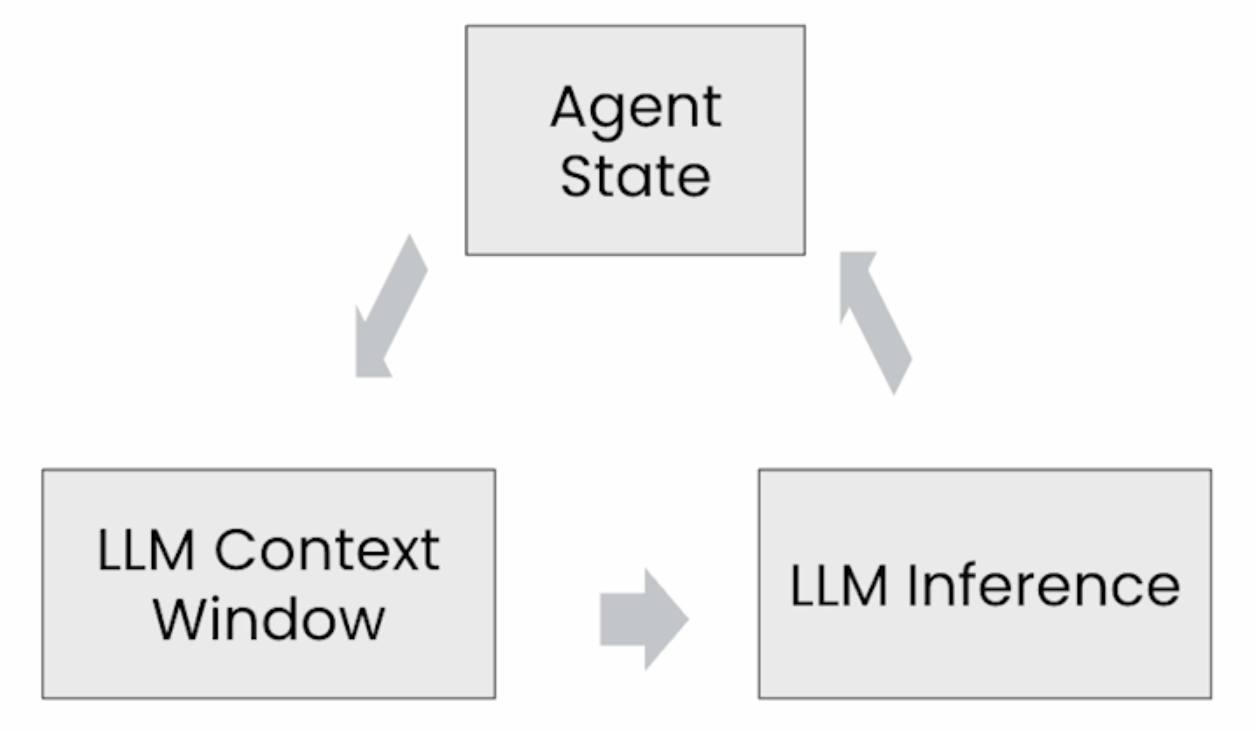
这里先来实现一个最简单的 Agent 内存读写。
- 初始化 LLM API Client
1 | from openai import OpenAI |
- 实现一个 KV Memory 结构,并提供 Function-Call Tool
1 | agent_memory = {"human": "", "agent": ""} |
- Prompt 设定,提供 Memory Context 管理的能力
1 | system_prompt = """you are a chatbot. |
- 调用 LLM 推理接口
1 | chat_completion = client.chat.completions.create( |
- 调用输出,memory 的 KV 更新成功
1 | Choice(finish_reason='tool_calls', index=0, logprobs=None, message=ChatCompletionMessage(content='\n\n', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_ortft9h7z3gh7l9r6kzt67w6', function=Function(arguments='{"section": "human", "memory": "QuantumForge"}', name='core_memory_save'), type='function')], reasoning_content='Okay, the user mentioned their name is QuantumForge. I need to save that into the core memory under the human section. Let me call the core_memory_save function. The parameters should be section "human" and memory "QuantumForge". Make sure the JSON is correctly formatted.\n')) |
深入 MemGPT
对于复杂 Agent 应用的 Prompt,可能会包含不同类型的上下文,如何拼接和生成对于的 Input Context 对 LLM 输出效果影响很大。
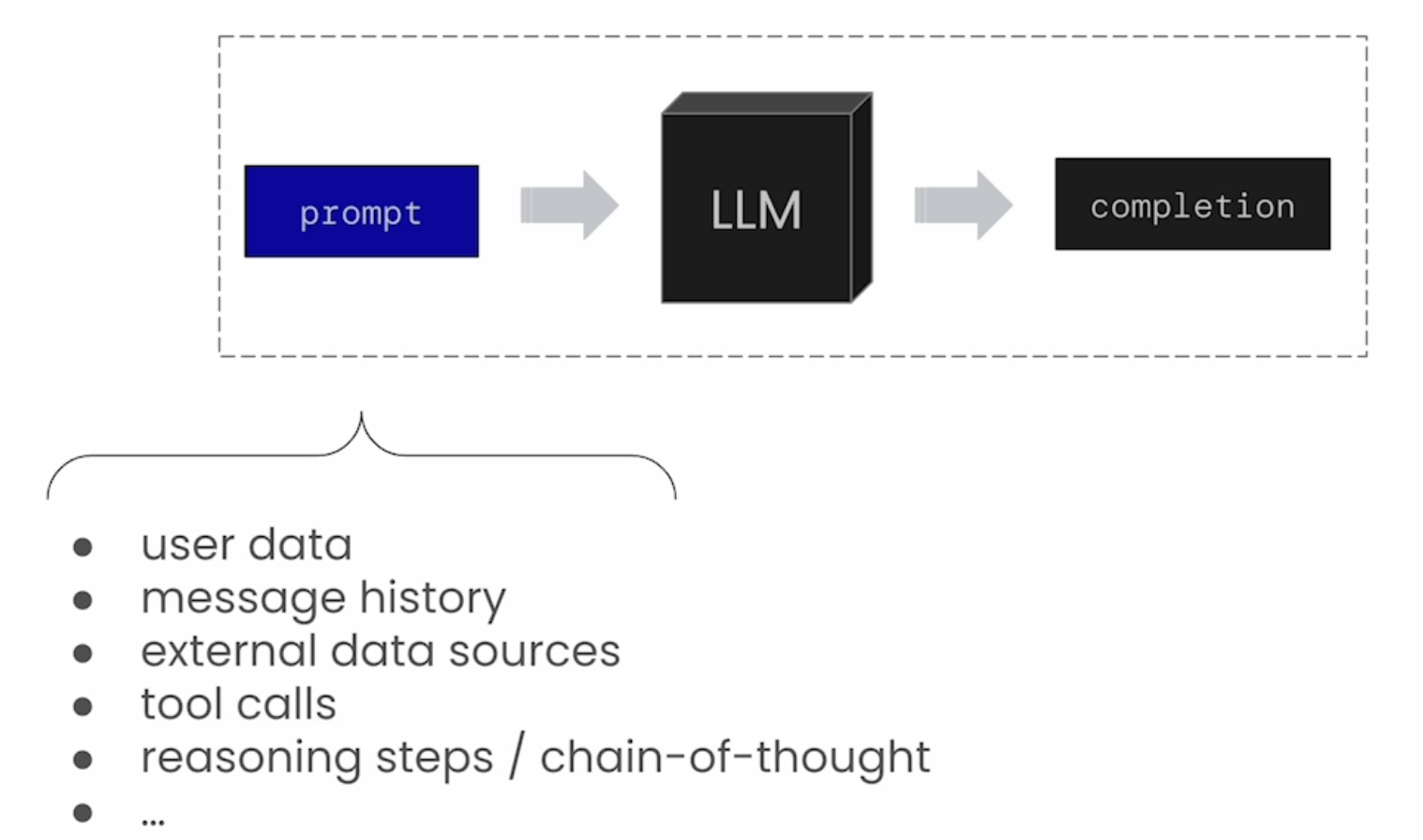
MemGPT 是在这个场景下,提供一套自动更新和管理 Agent Memory 的机制,下图的 LLM OS 扮演着类似操作系统里面的内存管理角色。
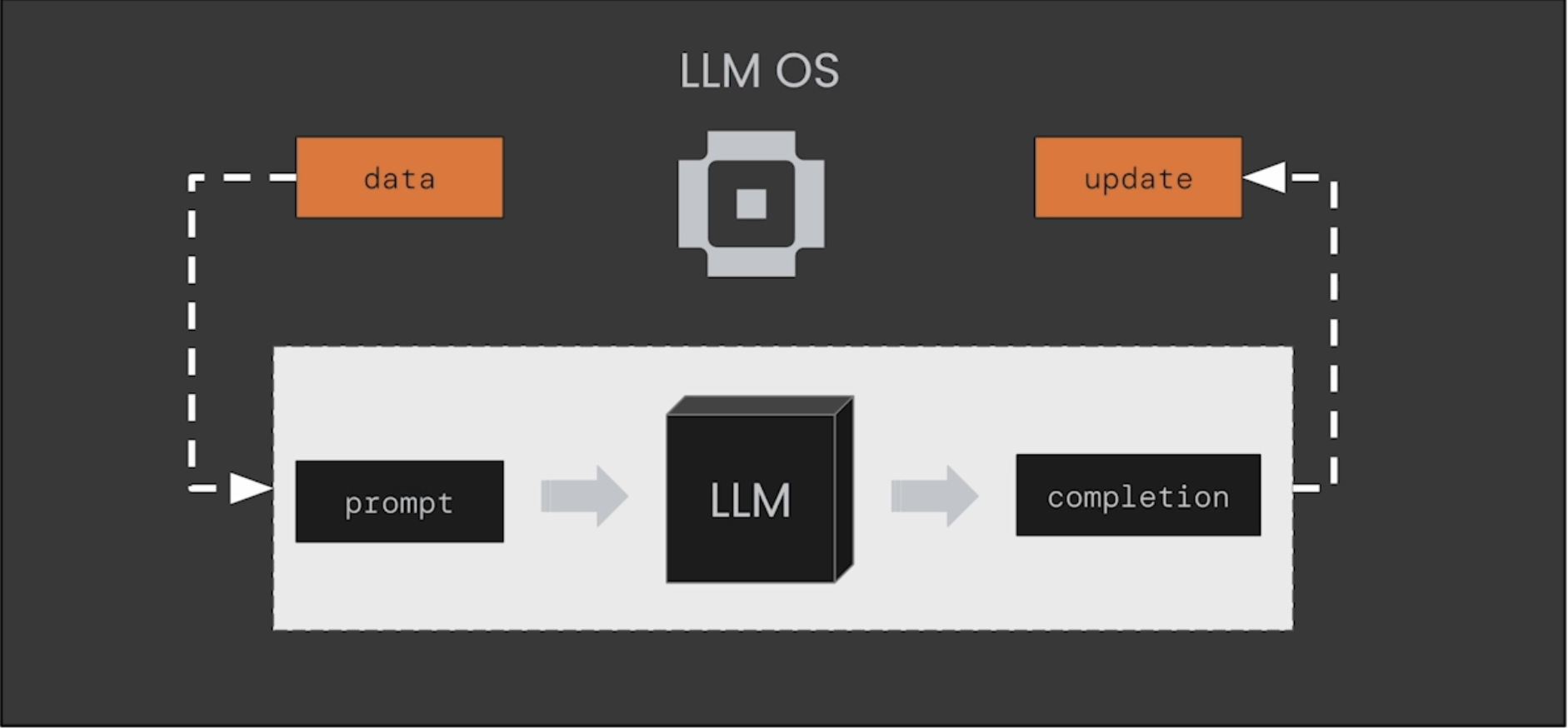
对于 MemGPT 来说,能够自主执行动作,并能够基于 Long-term Memory 来自我学习,关键点包括几个:
- Self-editing Memory:提供一个 Tool 能力,让 LLM 能读写状态内存,一些 System 设定或者 Instruction 信息可以存储到 MemGPT,Agent 可以通过会话过程中学到的新增信息来更新 Mem
- Inner-Thoughts:MemGPT Agent 会在回答用户问题之前,会有一个思考的过程
- Call-Tools:MemGPT 的输出都是 Call-Tools,比如和用户的沟通会去调用 send_message tool
- Looping via heartbeats:用户的一次 Input 会触发多轮 LLM 推理,MemGPT 在调用 Tool 时会设定一个心跳去触发下一个 Tool 调用
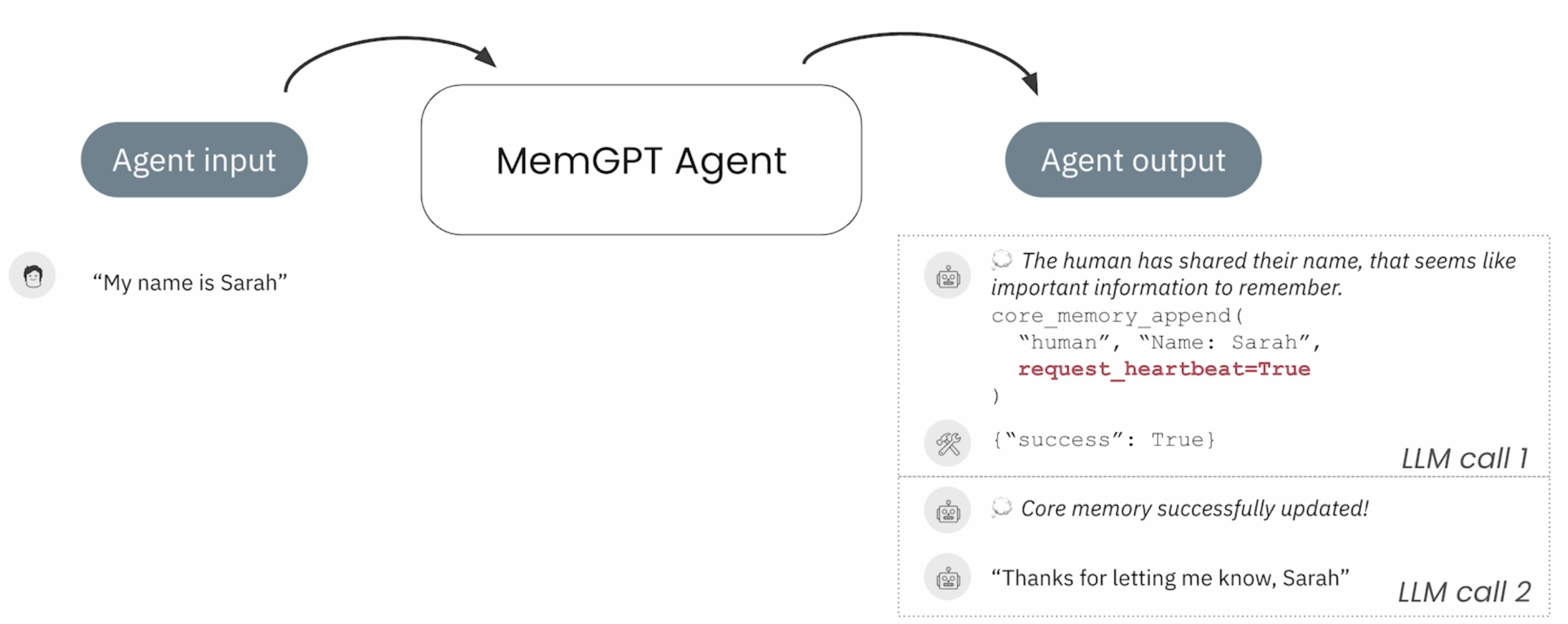
MemGPT Agent 会把 Memories、Tools、Messages 进行持久化存储到 Agent State,在 Query LLM 之前把 State 中的信息做 Context Compilation,筛选出必要的 Context 增加到 Prompt 中。
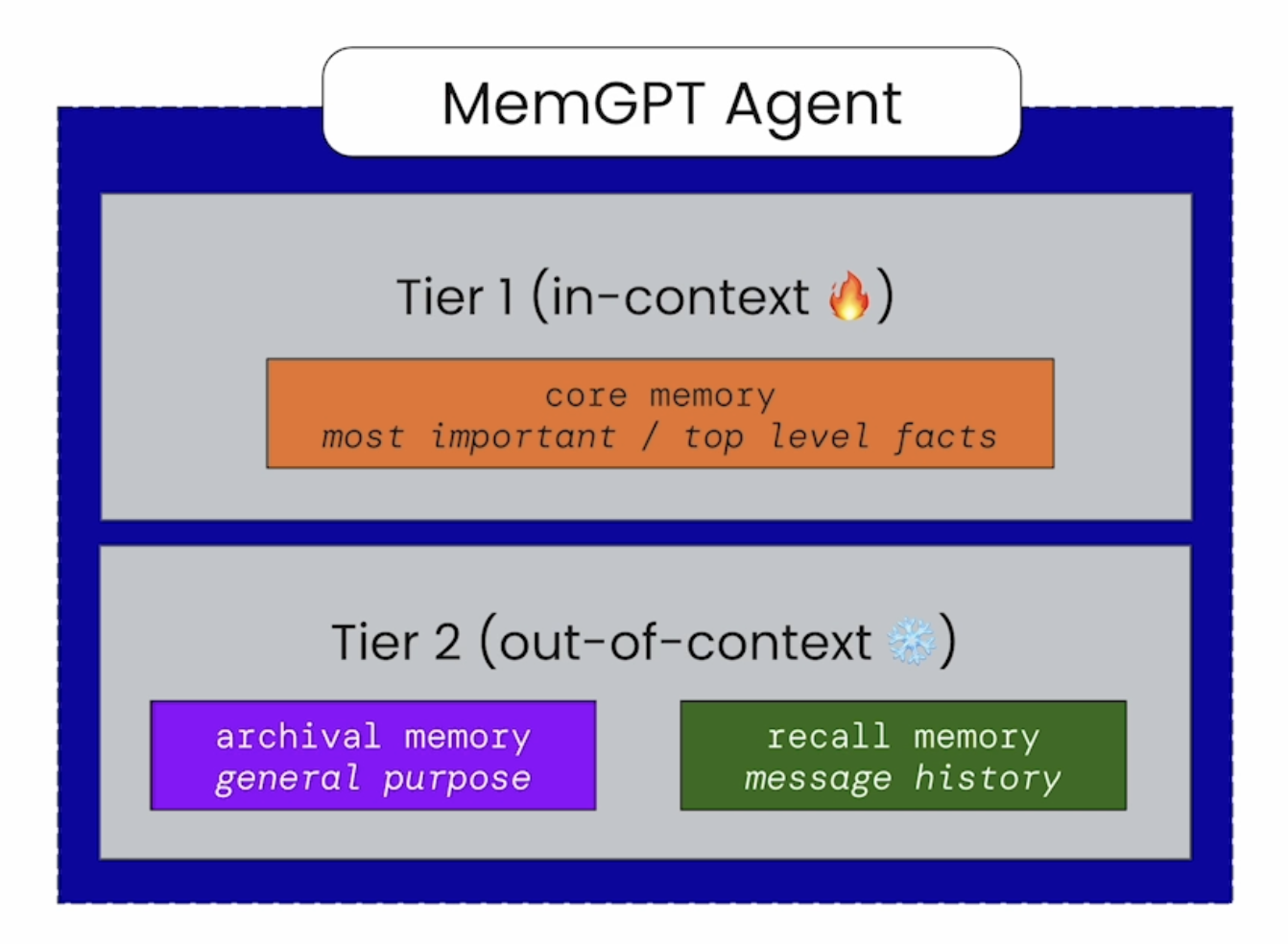
MemGPT 的 State 存储会分为两层结构:
Tier1 - In Context:
- core memory 存储,会储存重要且频繁访问的 Context,会有大小限制
- summary 信息,对于历史 messages 的 summary,避免过长的 in context window
Tier2 - Out of Context:recall/archival memory 会提供 stats 统计信息,帮助 agent 快速判断是否有关联信息
- recall memory:所有的 messages 历史,支持 agent 快速检索历史 messages
- archival memory:在 core memory 达到 Limit 限制时会写入 archival memory,同时 archival memory 也可以作为 RAG 数据源
MemGPT 实践
可以基于 Letta 来实现一个 MemGPT Agents。Agents 的能力主要通过:Prompts( system 或 users)、Tools、Memory 能力、Memory 内容(core & archival)来实现,这四个部分会在每一个 agent step 中拼接出 LLM Context 作为模型的输入。
详细实践可参考 Letta 用户文档。