内容总结自 Deeplearning.AI 的 Evaluating AI Agents 课程
在 AI Agents 的搭建过程中,我们需要搭建 Agent Pipeline,并观测整个 workflow 中的关键环节,评估每个环节的效果和优化方案,比如对于一个 AI Coding Agent,需要建设的模块包括:
- Workflow 流程:更新 Agent 的整体逻辑
- Plan 阶段:更新和优化 Prompt
- Use Tools 阶段:增加不同的工具和输入
- Reflect 阶段:调整 LLM 模型
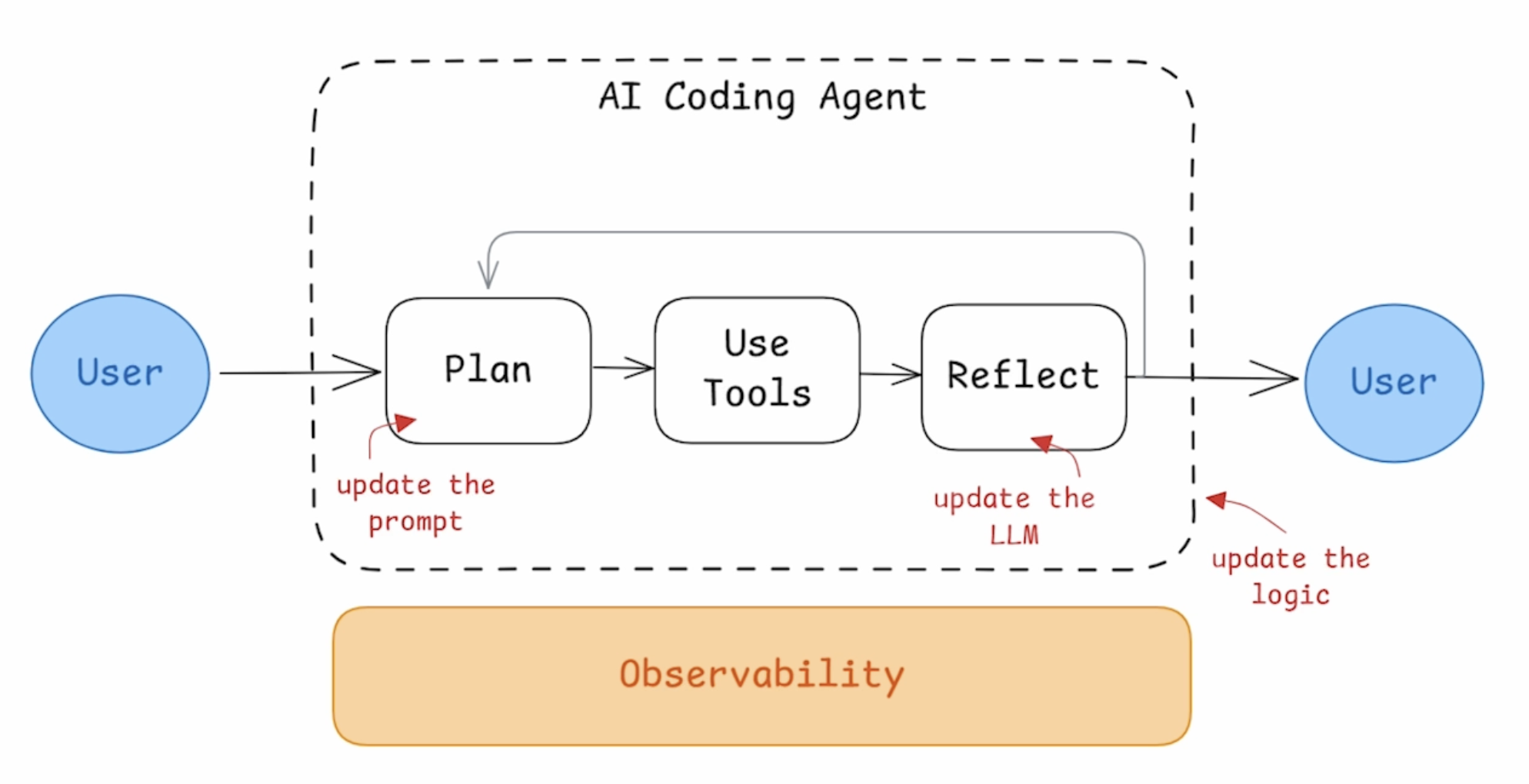
以下会通过来构建一个 Code Agent,并介绍如何做 Agent 效果的评估和迭代。
LLMs 效果评估
提到 LLM 评估,一般包括 model 评估和应用评估:
LLM model 评估:用 Benchmark datasets 评估基础模型的能力,常见的 datasets 包括:
- MMLU,覆盖数学、心理学、医学等的多选问题
- HumanEval,代码生成场景
LLM 应用评估:用测试集来验证整个 LLM 应用的效果,测试集来自人工编写、合成 case、实际业务数据
- 多个环节会影响 LLM 应用的效果,包括 Prompt、Tools、Memory、Routing 等
这里我们主要关注 LLM 应用评估。LLM 应用测试与传统应用测试有所不同:
- 传统应用测试面对的 case 在给定输入情况下,输出是相对确定性的,通过单元测试验证函数和代码片段的效果,通过集成测试验证整体应用表现;
- LLM 应用在给定输入情况下,输出会有一定的随机性,关注应用解决用户特定输入任务的能力,输出效果往往会关注相关性和连贯性,而非传统应用测试的 pass/failed
LLM 应用评估的类型包括:
- 幻觉(Hallucinations):LLM 是否能够准确理解上下文,并完成对应的工作
- 检索相关性(Retrieval Relevance):上下文和知识理解是否和用户 query 相关
- 回答准确性(Q&A Accuracy):回答是否匹配用户的需求
- 内容合规(Toxicity):回答是否包含有害和不合规的内容
- 性能表现(Summarization performance):应用的性能情况,可以通过开源评测 datasets 来验证
- 正确性&可读性(Correctness & Readability):主要用于代码生成场景
Agents 评估的作用
Agents 是基于用户输入,结合 LLM 的推理能力来完成特定的工作任务:
- 推理能力:LLM 模型
- 路由能力:理解用户的意图,决定使用合适的工具
- 动作执行:执行代码和工具,主要是基于 API 调用

Agents 在执行过程中可能会出问题的地方有哪些? 以一个规划旅行计划的 Agent 为例:
输入 query:预定一个去旧金山的计划
Agent 执行流程中可能出问题的地方:
- 路由能力:选择了错误的工具
- Function-call:比如调用 search API,调用参数错误
- 上下文:RAG 上下文错误
- 生成回答:回答不清晰或者包含不合规的内容
- 正确性:没有解决问题,用户不满意
AI 应用工程开发上,往往微调 Prompt 或者模型设置,带来的效果变化就非常显著。

下面会具体介绍集中在开发和生产环境中,用于提升 LLM 应用效果的工具和方法。这里我们引入开源的 Agent 观测工具 Arize Phoenix。
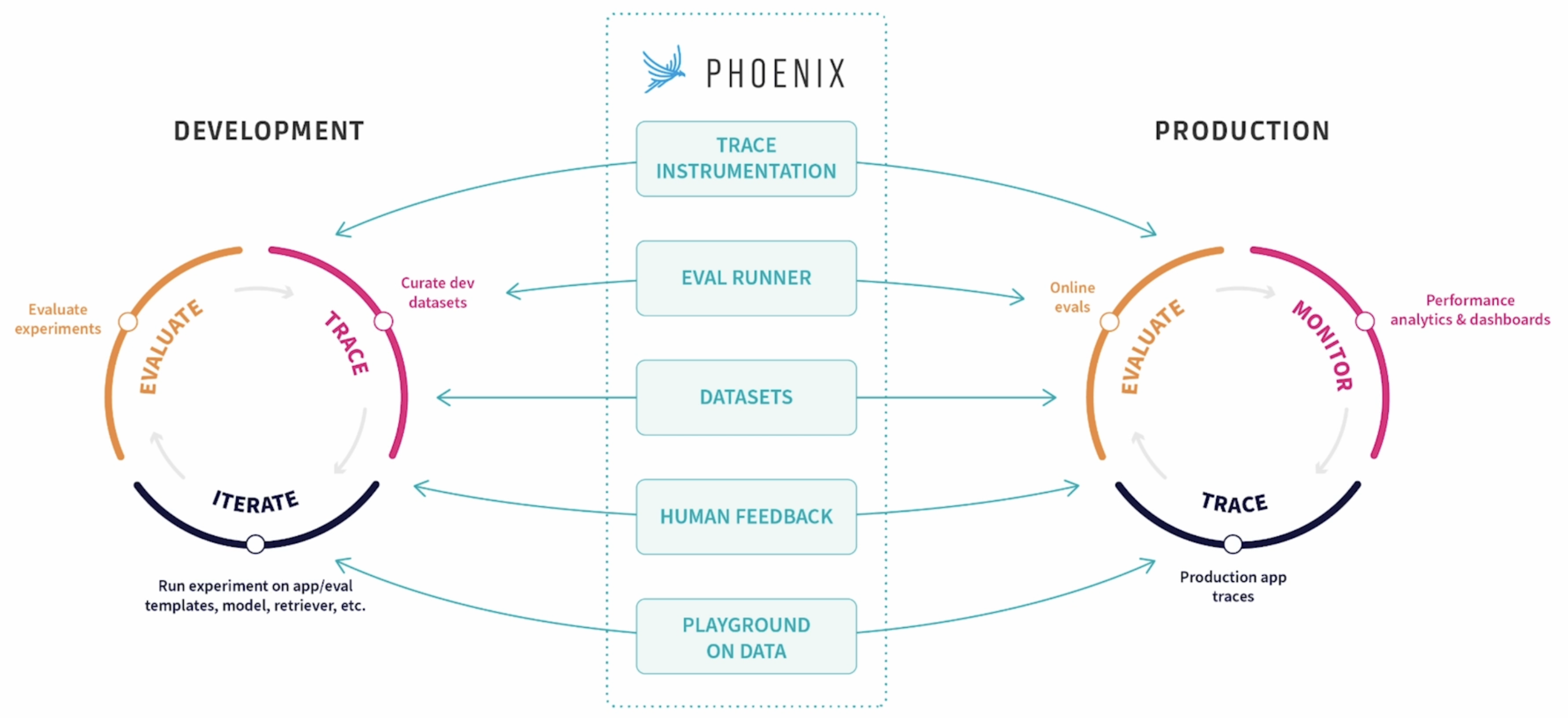
Tracing Agents
通过 Trace 来观测整个 Agent 的执行过程,Trace 会记录每一个执行步骤,并通过 Span 来呈现步骤中的关键数据,Trace 遵循 OpenTelemetry 规范。先安装 Arize Phoenix 依赖:
1 | pip install arize-phoenix arize-phoenix-otel |
本地用 docker 启动 Phoenix Server:
1 | docker run -d -p 6006:6006 -p 4317:4317 -i -t arizephoenix/phoenix:latest |
Trace Collector 的 Endpoint 为 COLLECTOR_ENDPOINT=``http://127.0.0.1:6006/v1/traces
增加 main span 代码,调用 run_agent Agent 主逻辑:
1 | def start_main_span(messages): |
Agent 主逻辑内容也增加 Tracer decorator,Tools 函数定义增加 @tracer.tool() Decorator 修饰。
1 | # ... |
执行 Agent 代码,在 http://127.0.0.1:6006 上拿到 Trace 记录。
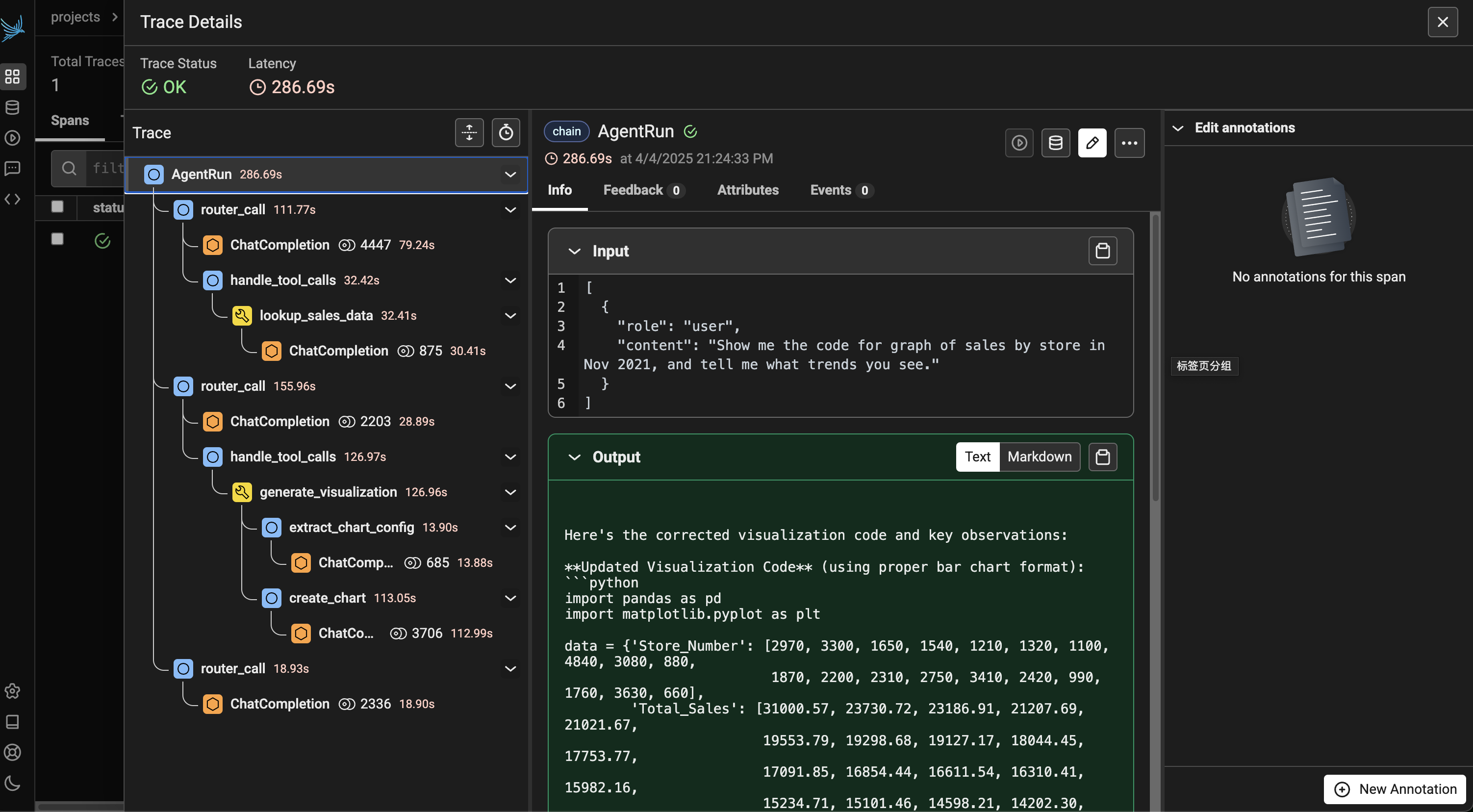
Router 和 Tools 评估
评估的手段主要分为三种:Code-Based Evals、LLM-as-a-Judge Evals、Human Annotations
Code-Based Evals
基于代码评估 Agent 的输出,类似传统的单测,执行一些验证代码,手段包括:
- 对输出结果进行正则匹配、Json 解析、关键词检查等
- 输出结果和 Expected outputs 进行比较,包括直接匹配、Cosine 相似度/距离等,这里需要有 ground-truth 的 Expected outputs
LLM-as-a-Judge Evals
用单独的 LLM 来判断 Agent 的输出质量,把 Agent 的输入和输出拼接形成新的 Prompt,并把对输出结果的评价标准加入到 Prompt,用 LLM 输出来判断 Agent 的效果。
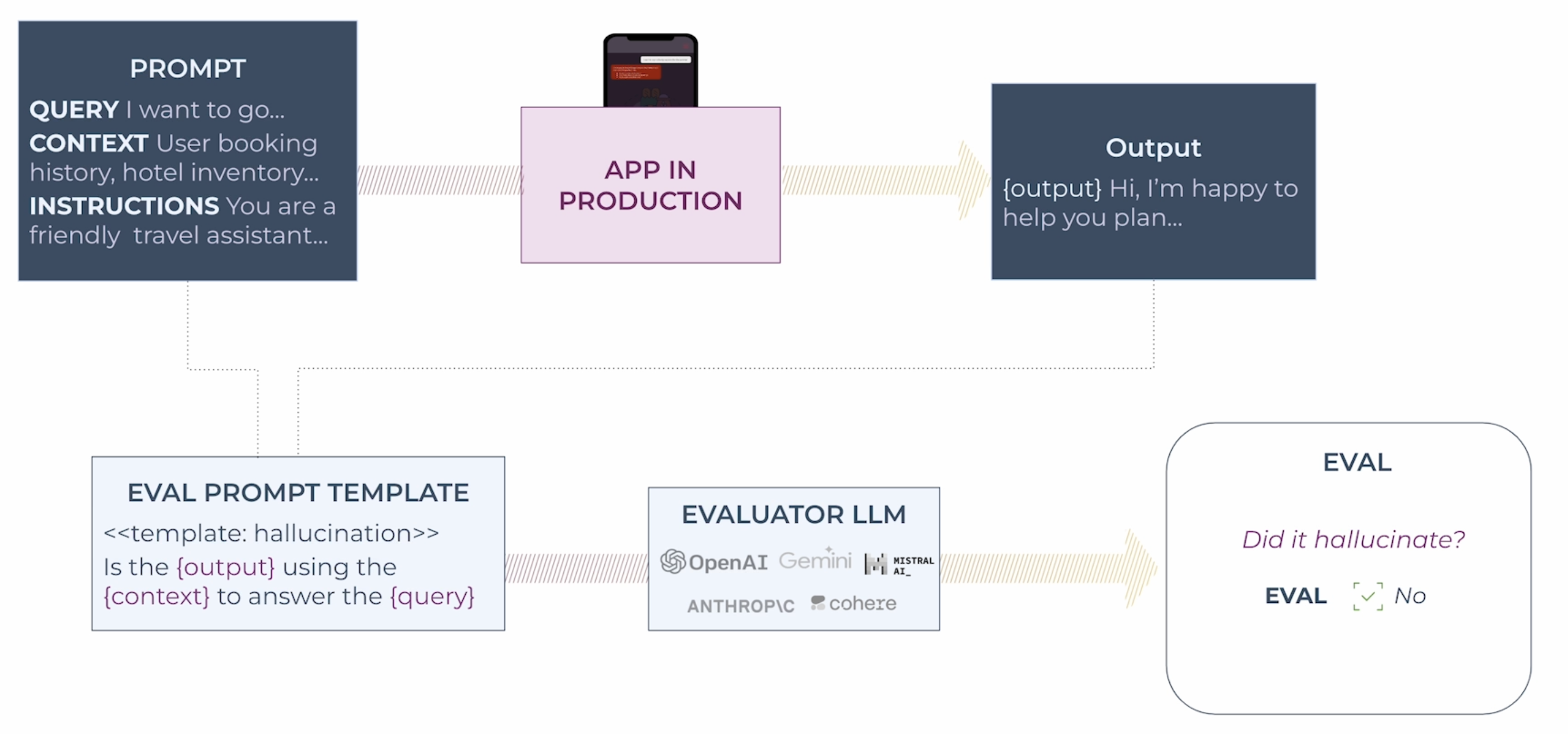
例如我们用 LLM 来评估一个 RAG retrieval span 的效果,注意 Eval Template 部分的 Prompt 内容。
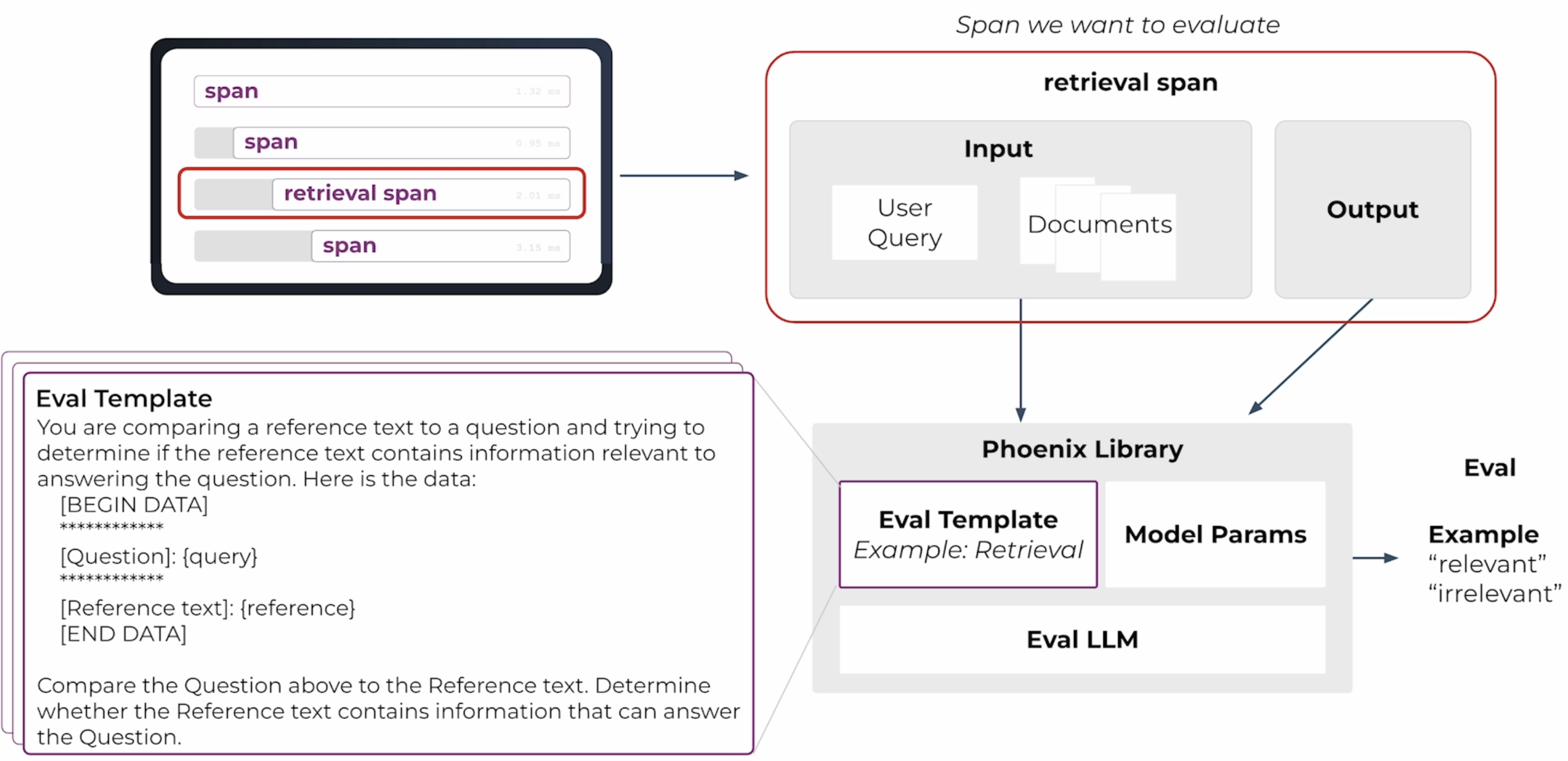
LLM-as-a-Judge 需要注意的关键点:
- 需要用 SOTA 的模型去做评估,比如 GPT-4o 和 Claude 3.5 Sonnet 等
- LLM-as-a-Judge 做不到 100% 正确性,这里错误评估可以通过迭代 Prompt 和模型来降低影响
- LLM-as-a-Judge 输出应当去给出离散的分类标签,应该是 正确 vs. 错误,而不是一个 1-100 的估分
Human Annotations
人工打标和用户反馈,可以通过一个人审队列来给出 Agent 的结果评估,或者是来自实际用户的反馈。
不同工具的区别可以从结果是否确定性,以及定量/定性两个维度来区分。
| 非确定性评估 | 确定性评估 | |
| 定性分析,相对灵活 | LLM-as-a-Judge | Human Annotations |
| 定量分析,模式固定 | Code-Based Evals |
人工评估给出确定性结果是最优的手段,实际规模化会受限于人力投入和成本,往往需要用 Code-Based Evals 和 LLM-as-a-Judge 来辅助快速迭代。
Router 评估
Router 的评估主要关注两个点:
- Function-Calling 选择:Router 是否选择了正确的 Function
- 入参提取:Router 是否从用户输入中提取出正确的 Function 参数
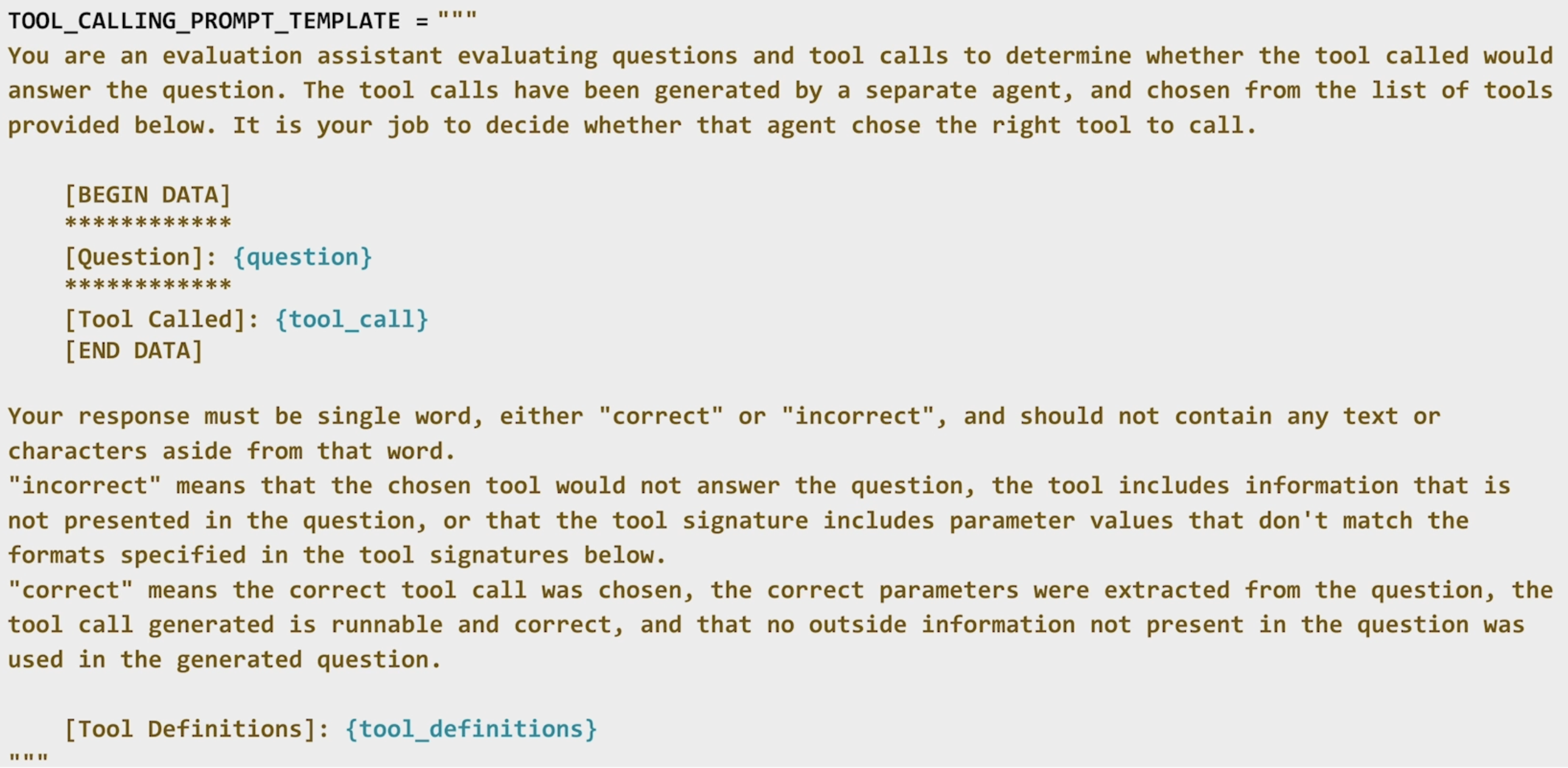
以下是使用 LLM-as-a-Judge 来评估 Router 的 Prompt 模板,Prompt 包含几个部分:评估背景、上下文信息(问题、选中的 Tool)、评估标准、tools 定义等。
Tools 评估
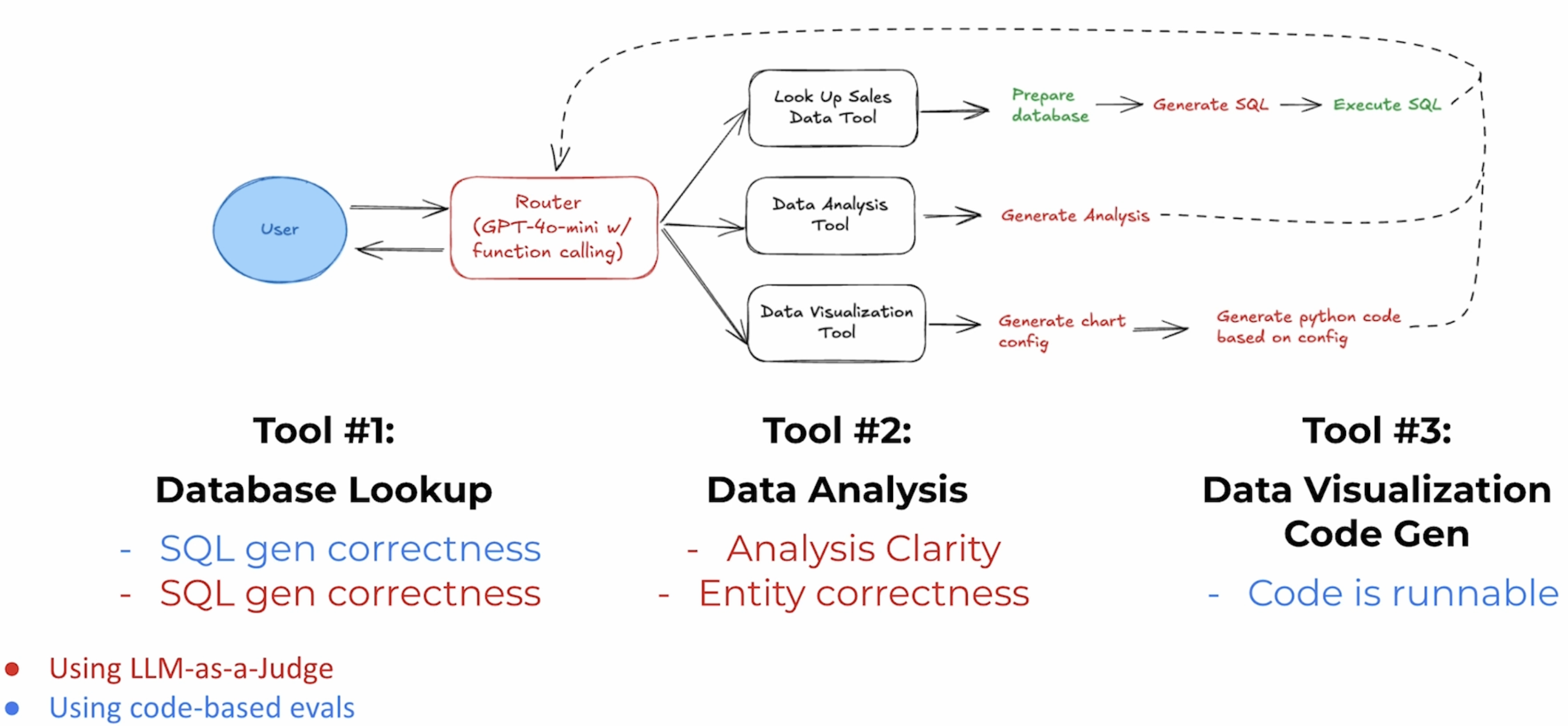
Tools 评估可以通过 LLM(相关性、幻觉、可读性、正确性等)或者 Code-Based Evals(正则匹配、Json 解析等)。对于之前 Code Agent 的 Tools 评估:
- Tool#1 数据库查询:SQL 正确性验证,可以用 LLM 或者 Code-Based Evals
- Tool#2 数据分析:主要依赖 LLM 来做可读性和正确性的验证
- Tool#3 代码生成:Code-Based Evals,验证代码是否可以运行
这里以 Router 的评估为例,评估逻辑代码:
1 | # 从 Phoenix 中加载 Tools Router 的 Spans |
执行后评估结果如图:
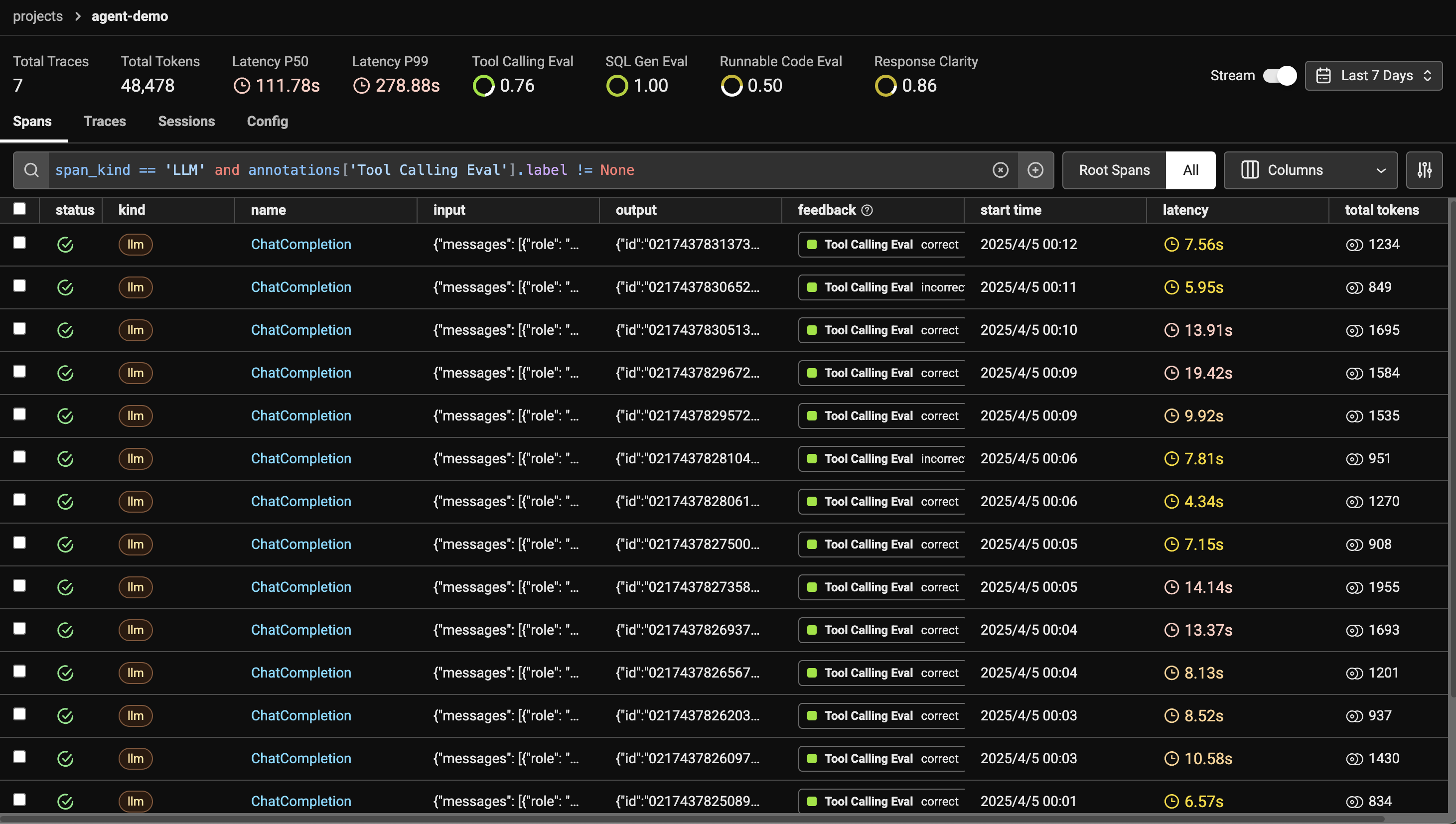
可以在实际项目中,结合不同的需要去使用这些 Evaluation 工具。
执行路径评估
执行路径是指在给定用户输入情况下,Agent 的处理过程(包括 Router、Tools、逻辑处理等)。
- Input:Which store had the most sales in 2021?,执行路径:

- Input:Plot daily sales volume over time,执行路径:
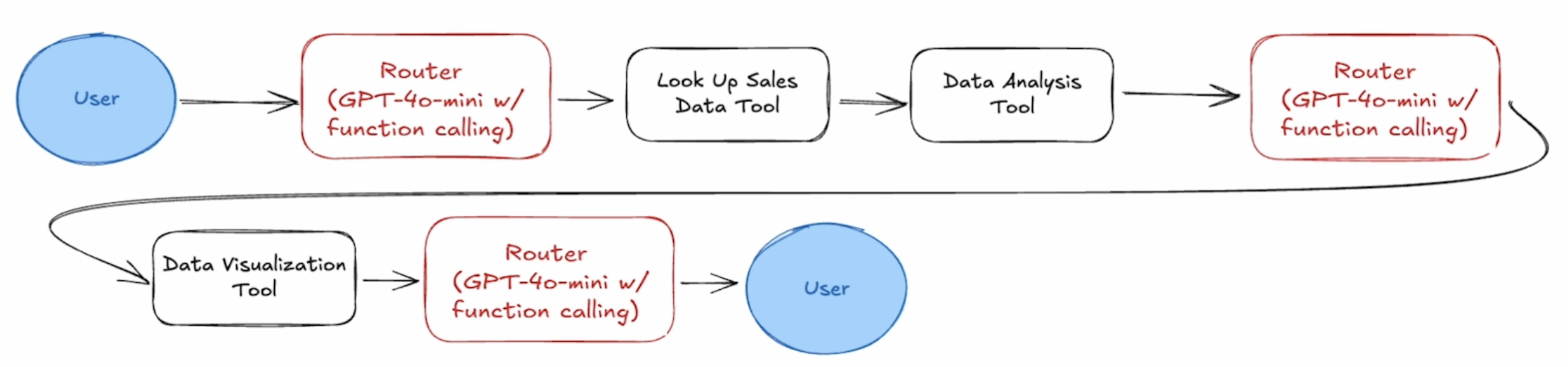
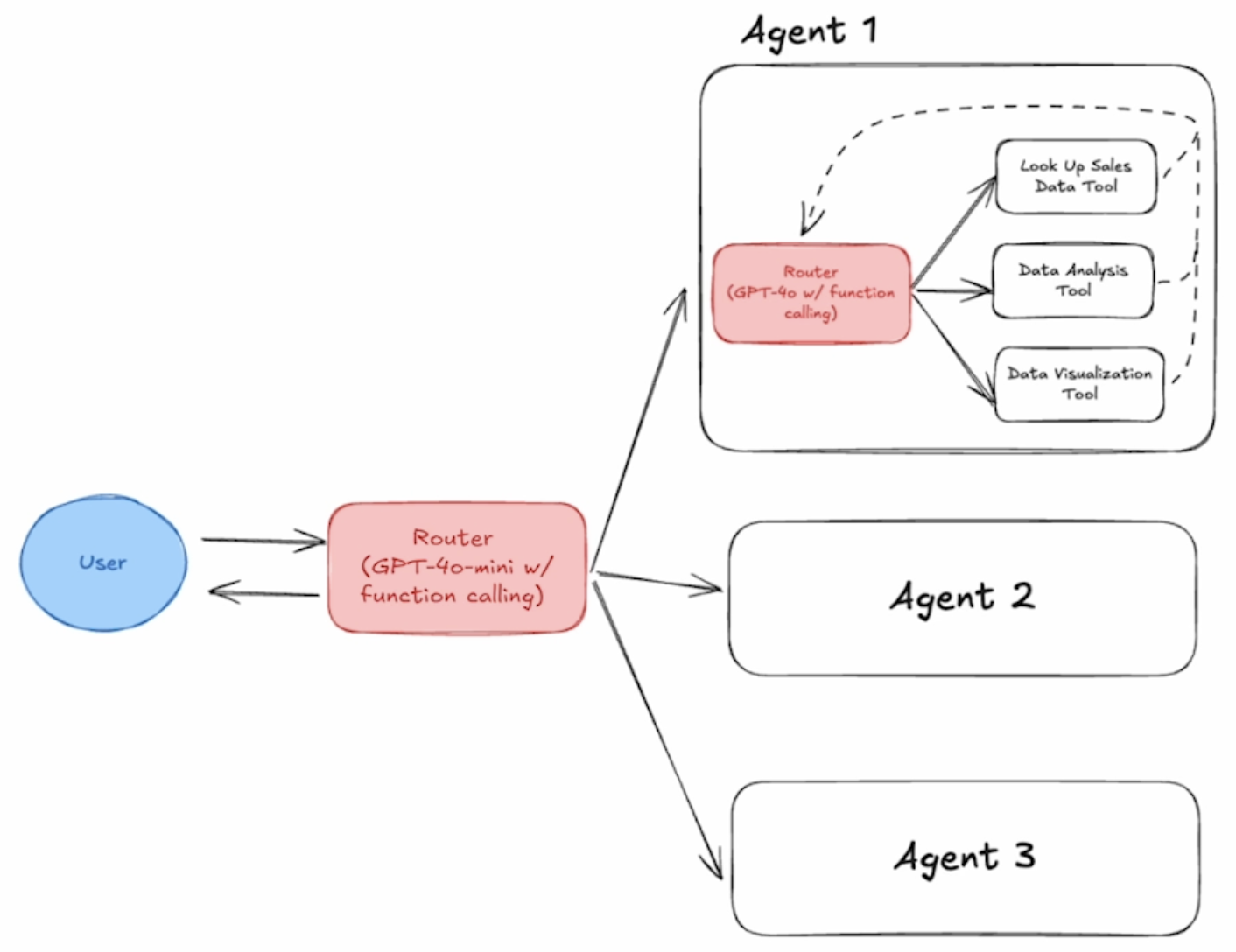
在多 Agent 应用中,执行路径会变得非常复杂,不同的路径 执行效率 和 正确性 区别很大。
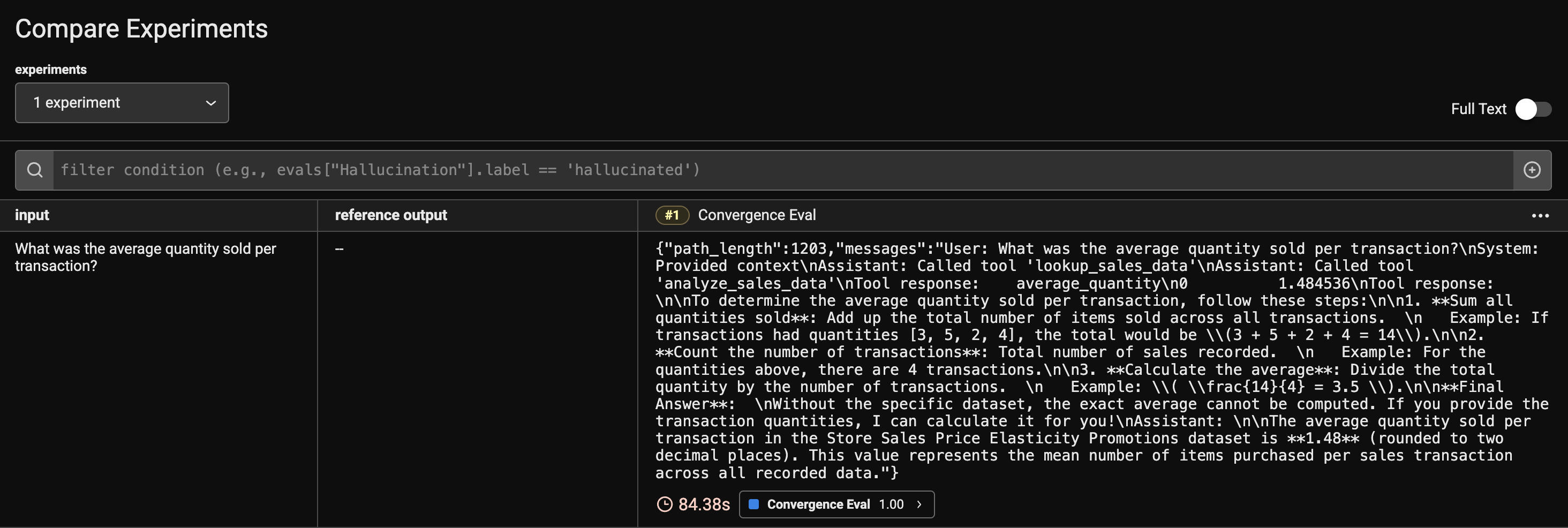
Agent 在给定输入下的执行路径和理想路径的偏差一般使用 Convergence 来评估,Convergence 的计算方法:
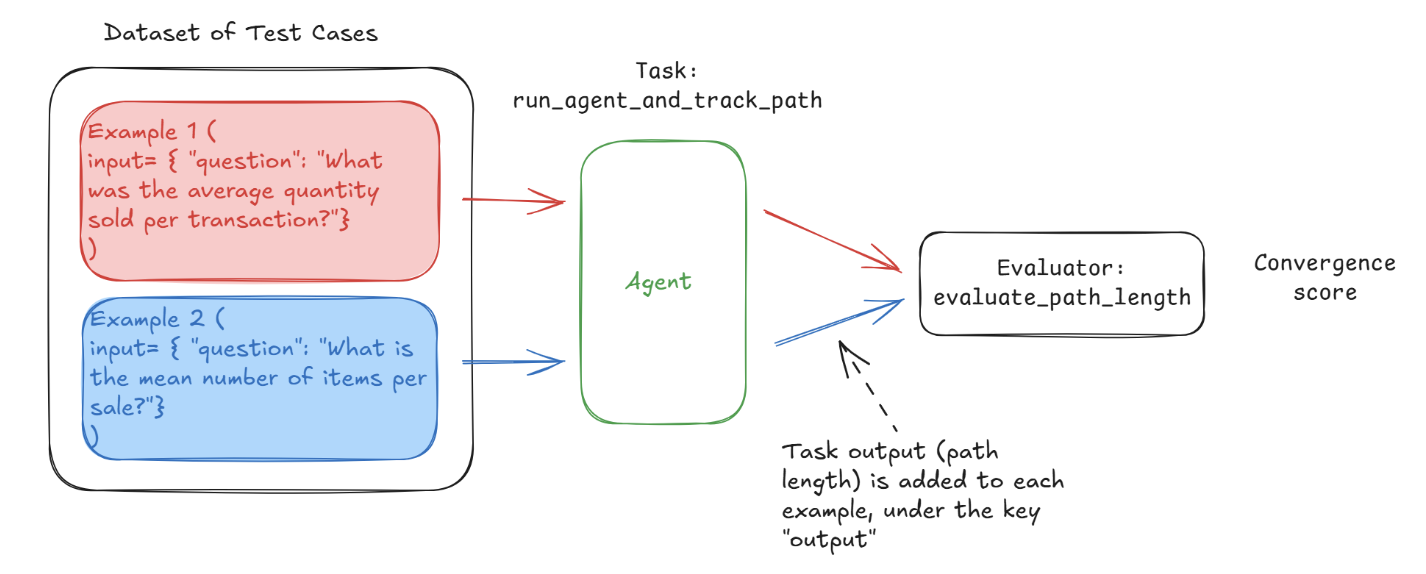

Convergence 评估的是 Agent 在给定输入下执行了理想路径的概率,如果 Convergence 为 1,则表示 100% 选择了理想路径。下面是 Convergence 评估的示例代码:
1 | convergence_questions = [ |
在 Phoenix 平台上看到 Convergence 的评估记录:
集成测试
Phoenix 提供了 Experiment 的脚手架,帮助在迭代中可以重复运行测试 case,用来评估 Agent 的效果。
1 | from phoenix.experiments import run_experiment |